
(चेन रूल और आंशिक अवकलज – मल्टीलेयर नेटवर्क में Gradient की कुंजी)
🔷 1. परिचय (Introduction)
Deep Learning में हर layer interconnected होती है, और output पर effect डालती है।Gradient को backward propagate करने के लिए हम दो concepts पर निर्भर करते हैं:
- Partial Derivatives (∂)
- Chain Rule
यह अध्याय Neural Networks की training को समझने में केंद्रीय भूमिका निभाता है।
🔹 2. Partial Derivatives (आंशिक अवकलज)
➤ परिभाषा:
जब किसी फंक्शन में एक से अधिक variable हों (multivariable function), तब किसी एक variable के respect में निकाले गए derivative को Partial Derivative कहते हैं।
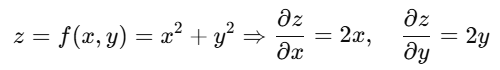
📌 Deep Learning में उपयोग:
- Loss Function कई weights पर निर्भर करता है
- हर weight का gradient आंशिक अवकलज से निकाला जाता है
- Vector form में ये gradients बनाते हैं: Gradient Vector
🔹 3. Chain Rule (श्रृंखलित नियम)
➤ परिभाषा:
जब एक function दूसरे function के अंदर होता है (nested function), तब derivative निकालने के लिए हम Chain Rule का उपयोग करते हैं।
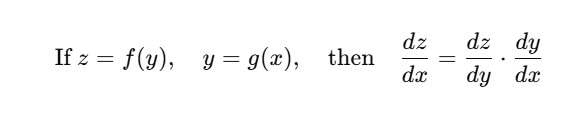
➤ Deep Learning Analogy:
मान लीजिए:
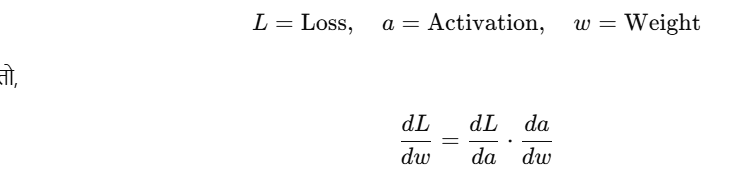
👉 यही Backpropagation में होता है — gradients हर layer से पीछे propagate होते हैं।
📉 4. Multivariable Chain Rule Example
मान लीजिए:
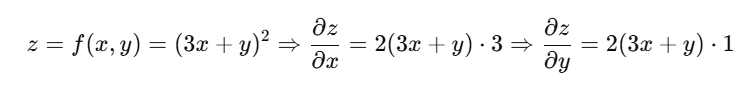
💡 Visualization Idea:
Loss L
↑
Activation a = f(w·x + b)
↑
Weight w
We want:
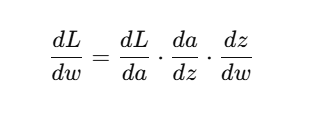
PyTorch में Automatic Chain Rule
import torch
x = torch.tensor(2.0, requires_grad=True)
y = x**2 + 3 * x + 1
y.backward()
print("dy/dx:", x.grad) # Output: dy/dx = 2x + 3 = 7
🎯 Chapter Objectives (लक्ष्य)
- Partial Derivative की परिभाषा और गणना समझना
- Chain Rule के पीछे का सिद्धांत जानना
- Deep Learning में gradient propagation कैसे होता है, इसे समझना
- Real model में gradients कैसे जुड़ते हैं, यह देखना
📝 अभ्यास प्रश्न (Practice Questions)
- Partial Derivative किसे कहते हैं? उदाहरण सहित समझाइए।
- Chain Rule का उपयोग कहाँ किया जाता है?
- Deep Learning में Chain Rule का वास्तविक उपयोग किस चरण में होता है?
- नीचे दिए गए कोड का आउटपुट क्या होगा?
x = torch.tensor(3.0, requires_grad=True)
y = (2*x + 1)**2
y.backward()
print(x.grad)