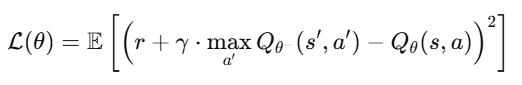आपने Reinforcement Learning की core technique Q-Learning को समझा — अब हम उसी का Deep Learning version सीखेंगे: 🧠 Deep Q-Network (DQN)
🔶 1. What is DQN?
Deep Q-Network (DQN) एक ऐसा algorithm है जो traditional Q-Learning को Deep Neural Network से combine करता है। जब state space बहुत बड़ा या continuous होता है (जैसे images, video frames), वहाँ Q-table बनाना possible नहीं होता — इसलिए हम use करते हैं Neural Network to approximate the Q-function: Q(s,a)≈Qθ(s,a)
🎯 “DQN maps states to Q-values using a deep neural network.”
📈 2. Why DQN?
Limitation of Q-Learning
DQN का समाधान
Large state-action space
Neural network approximation
Slow convergence
Experience replay
Instability in training
Target networks
🧠 3. Key Concepts in DQN
🔹 a) Q-Network
A deep neural network takes state as input
Outputs Q-values for each possible action
🔹 b) Experience Replay Buffer
Past experiences (s,a,r,s′) store किए जाते हैं
Random mini-batches से training होती है → reduces correlation
🔹 c) Target Network
Q-value targets एक fixed target network से लिए जाते हैं
Target network को हर कुछ steps पर update किया जाता है
इससे training stable होता है
🧪 4. DQN Architecture (High Level)
Input: State (e.g., image pixels) ↓ Convolutional Layers (if image input) ↓ Fully Connected Layers ↓ Output: Q-values for all possible actions
🔁 5. DQN Training Loop
Initialize Q-network (Q) and target network (Q_target) Initialize replay memory D
For each episode: Initialize state s For each step in episode: Choose action a using ε-greedy policy on Q(s) Execute action a → observe reward r and next state s' Store (s, a, r, s') in replay memory D
Sample random mini-batch from D: For each (s, a, r, s'): target = r + γ * max_a' Q_target(s', a') loss = (Q(s, a) - target)^2 Backpropagate and update Q
Every N steps: Q_target ← Q # update target network