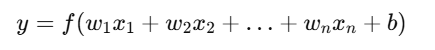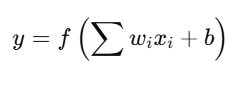(हानि फलन और अनुकूलन विधियाँ)
🔷 1. Loss Function (हानि फलन) क्या है?
Loss function यह मापता है कि आपके मॉडल की prediction असली output से कितनी दूर है।
🔁 Role in Training:
- Prediction → Loss Function → Error → Backpropagation → Weight Update
📌 कार्य:
| Step | कार्य |
|---|---|
| Prediction | Output generate करना |
| Loss | गलती मापना |
| Backpropagation | Gradient निकालना |
| Optimizer | Weights update करना |
🔹 2. Loss Function के प्रकार
🔸 A. Regression Problems के लिए:
✅ Mean Squared Error (MSE):

- Continuous values के लिए
- Output को penalize करता है अगर prediction और label का अंतर बड़ा हो
✅ Mean Absolute Error (MAE):

- Outliers से कम प्रभावित
🔸 B. Classification Problems के लिए:
✅ Binary Cross Entropy:
L=−[ylog(p)+(1−y)log(1−p)]
- Binary classification के लिए
- Sigmoid + BCELoss
✅ Categorical Cross Entropy:

- Multi-class classification
- Softmax + CrossEntropyLoss
💻 PyTorch Examples:
import torch
import torch.nn as nn
# MSE Loss
mse_loss = nn.MSELoss()
pred = torch.tensor([2.5])
target = torch.tensor([3.0])
print("MSE:", mse_loss(pred, target).item())
# Binary Cross Entropy
bce_loss = nn.BCELoss()
pred = torch.tensor([0.9])
target = torch.tensor([1.0])
print("BCE:", bce_loss(pred, target).item())
🔧 3. Optimization (अनुकूलन)
Optimizer वह algorithm है जो model के weights को loss minimize करने के लिए update करता है।
🔸 4. Common Optimization Algorithms
| Optimizer | Description |
|---|---|
| SGD | Simple gradient descent |
| Momentum | Adds momentum to SGD updates |
| RMSProp | Adaptive learning rate, good for RNN |
| Adam | Adaptive + Momentum = Most widely used |
🔁 Gradient Descent Update Rule:

जहाँ:
- η: Learning rate
- ∂L/∂w: Gradient of loss w.r.t. weights
⚠️ Learning Rate की भूमिका:
| Learning Rate | परिणाम |
|---|---|
| बहुत छोटा | Slow training |
| बहुत बड़ा | Overshooting, unstable |
| सही | Fast & stable convergence |
💻 PyTorch में Optimizer:
import torch.optim as optim
model = torch.nn.Linear(1, 1)
optimizer = optim.Adam(model.parameters(), lr=0.01)
# Example training step:
loss = torch.tensor(0.5, requires_grad=True)
loss.backward()
optimizer.step()
optimizer.zero_grad()
🎯 Objectives Summary
- Loss function prediction error को मापता है
- Optimizers gradients का उपयोग कर weights को update करते हैं
- PyTorch में loss + optimizer combo सबसे जरूरी सेटअप है
📝 अभ्यास प्रश्न (Practice Questions)
- Loss Function और Optimizer में क्या अंतर है?
- MSE और MAE में क्या अंतर है?
- Binary Cross-Entropy का फॉर्मूला लिखिए
- Adam Optimizer कैसे काम करता है?
- नीचे दिए गए कोड का output क्या होगा?
loss = torch.tensor(1.0, requires_grad=True) loss.backward() print(loss.grad)