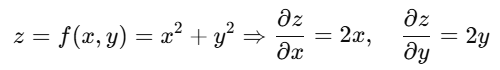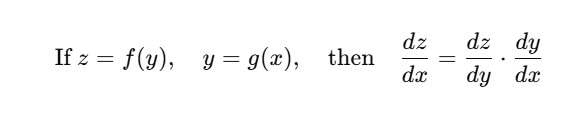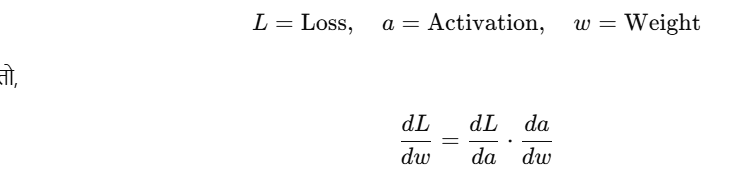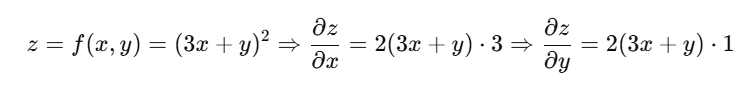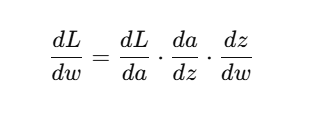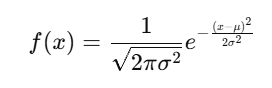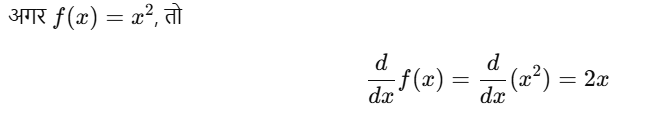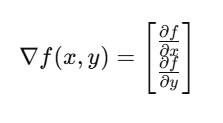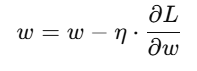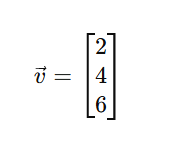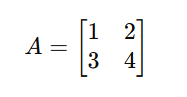(चेन रूल और आंशिक अवकलज – मल्टीलेयर नेटवर्क में Gradient की कुंजी)
🔷 1. परिचय (Introduction)
Deep Learning में हर layer interconnected होती है, और output पर effect डालती है।Gradient को backward propagate करने के लिए हम दो concepts पर निर्भर करते हैं:
Partial Derivatives (∂)
Chain Rule
यह अध्याय Neural Networks की training को समझने में केंद्रीय भूमिका निभाता है।
🔹 2. Partial Derivatives (आंशिक अवकलज)
➤ परिभाषा:
जब किसी फंक्शन में एक से अधिक variable हों (multivariable function), तब किसी एक variable के respect में निकाले गए derivative को Partial Derivative कहते हैं।
📌 Deep Learning में उपयोग:
Loss Function कई weights पर निर्भर करता है
हर weight का gradient आंशिक अवकलज से निकाला जाता है
Vector form में ये gradients बनाते हैं: Gradient Vector
🔹 3. Chain Rule (श्रृंखलित नियम)
➤ परिभाषा:
जब एक function दूसरे function के अंदर होता है (nested function), तब derivative निकालने के लिए हम Chain Rule का उपयोग करते हैं।
➤ Deep Learning Analogy:
मान लीजिए:
👉 यही Backpropagation में होता है — gradients हर layer से पीछे propagate होते हैं।
📉 4. Multivariable Chain Rule Example
मान लीजिए:
💡 Visualization Idea:
Loss L ↑ Activation a = f(w·x + b) ↑ Weight w
We want:
PyTorch में Automatic Chain Rule
import torch
x = torch.tensor(2.0, requires_grad=True) y = x**2 + 3 * x + 1
(प्रायिकता और सांख्यिकी – Deep Learning की गणितीय नींव)
🔷 1. परिचय (Introduction)
Probability और Statistics, Deep Learning की अनिश्चितताओं से निपटने की क्षमता का आधार हैं। Neural Networks noisy data, uncertain predictions, और stochastic optimization पर आधारित होते हैं, इसलिए इन दोनों शाखाओं की समझ अत्यंत आवश्यक है।
🔢 2. Probability (प्रायिकता)
➤ परिभाषा:
Probability किसी घटना के घटने की संभावना को मापती है।
उदाहरण:
उदाहरण: सिक्का उछालने पर Head आने की प्रायिकता: P(Head)=1/2
📌 Deep Learning में उपयोग:
उपयोग क्षेत्र
भूमिका
Dropout
Randomly neurons को हटाना (probability आधारित)
Bayesian Neural Nets
Uncertainty modeling
Classification
Probabilities में output (Softmax)
Sampling
Random initialization, augmentation
📊 3. Statistics (सांख्यिकी)
➤ परिभाषा:
Statistics का कार्य है डेटा को संगठित करना, विश्लेषण करना और सारांश निकालना।
📌 मुख्य सांख्यिकीय माप:
माप
सूत्र/उदाहरण
Mean (औसत)
xˉ=1/n ∑xi
Median (मध्य)
मध्य मान (sorted list में बीच का मान)
Mode (मोड)
सबसे अधिक बार आने वाला मान
Variance (σ2)
1/ n ∑(xi−xˉ)2
Standard Deviation (σ)
sqrt Variance
📌 Deep Learning में Statistics के उपयोग:
क्षेत्र
उपयोग
Data Normalization
Mean & Std से scaling
BatchNorm Layers
Running Mean और Variance
Evaluation
Accuracy, Confusion Matrix
Loss Analysis
Distribution plotting (e.g., Histogram)
🧠 4. Random Variables & Distributions
➤ Random Variable:
ऐसा variable जो किसी प्रयोग के परिणाम पर निर्भर करता है।
➤ Common Distributions:
नाम
उपयोग
Bernoulli
Binary classification (0 या 1)
Binomial
Repeated binary trials
Normal (Gaussian)
Image, speech data – most natural data
Uniform
Random weight initialization
Poisson
Rare event modeling
📉 Normal Distribution Formula:
(Statistics & Probability in PyTorch)
import torch
# Random Normal Distribution Tensor data = torch.randn(1000)
Calculus, विशेष रूप से Differential Calculus, Deep Learning में उस प्रक्रिया को दर्शाता है जिससे हम यह समझते हैं कि एक फ़ंक्शन का आउटपुट, उसके इनपुट में हुए छोटे बदलाव से कैसे प्रभावित होता है।
Deep Learning में “Gradient Descent” और “Backpropagation” इन्हीं सिद्धांतों पर आधारित हैं।
🔹 2. Derivative क्या होता है?
➤ परिभाषा:
किसी फ़ंक्शन f(x) का Derivative यह बताता है कि x में एक छोटी-सी वृद्धि करने पर f(x) में कितना बदलाव आता है।
उदाहरण:
🔧 Deep Learning में उपयोग:
Derivative बताता है कि Loss Function कितनी तेज़ी से बदल रहा है।
इससे हम जान पाते हैं कि weights को बढ़ाना चाहिए या घटाना, ताकि Loss कम हो।
🔹 3. Chain Rule
जब एक फ़ंक्शन दूसरे फ़ंक्शन के अंदर छुपा हो (nested function), तब Derivative निकालने के लिए Chain Rule का उपयोग होता है।
उदाहरण:
🔁 Backpropagation इसी principle पर आधारित है – यह हर layer के output का derivative पिछले layers तक propagate करता है।
🔹 4. Gradient क्या है?
➤ परिभाषा:
Gradient, एक multi-variable function का vector derivative होता है। यह उस दिशा को दिखाता है जिसमें function सबसे तेजी से बढ़ता या घटता है।
➤ Deep Learning में Gradient का उपयोग:
Model के weights और biases को अपडेट करने के लिए
Gradient Descent के माध्यम से Loss को minimize करने के लिए
💻 आवश्यक कोड (PyTorch में Gradient निकालना)
import torch
# Variable with gradient tracking enabled x = torch.tensor(2.0, requires_grad=True)
Gradient Descent और Backpropagation में Calculus की भूमिका जानना
📝 अभ्यास प्रश्न (Practice Questions)
Derivative का Deep Learning में क्या कार्य है?
Chain Rule किसलिए उपयोग होता है?
Gradient क्या दर्शाता है और इसे क्यों निकाला जाता है?
यदि f(x)=x3 तो f′(x) क्या होगा?
नीचे दिए गए PyTorch कोड का आउटपुट बताइए:
6. नीचे दिए गए PyTorch कोड का आउटपुट बताइए:
x = torch.tensor(3.0, requires_grad=True) y = x**3 y.backward() print(x.grad)
🔹Deep Learning मॉडल का उद्देश्य होता है कि वह सही prediction करे। इसके लिए हमें Loss Function को न्यूनतम (minimize) करना होता है। यह कार्य Gradient Descent नाम की optimization तकनीक से होता है।
🔹 5. Gradient Descent क्या है?
➤ परिभाषा:
Gradient Descent एक iterative optimization algorithm है जिसका उपयोग Loss Function को कम करने के लिए किया जाता है। यह हमेसा gradient की उल्टी दिशा में चलता है – जहाँ loss कम होता है।
🔁 “उतरती पहाड़ी पर सही रास्ते से नीचे जाना।”
🔹 6. Gradient Descent का सूत्र
मान लीजिए हमारा वेट w है, और हमने उसका gradient निकाला है ∂L/∂w तो नया वेट होगा:
जहाँ:
η = Learning rate (0.001, 0.01 etc.)
∂L/∂w = Gradient of Loss function
🔹 7. Learning Rate का महत्व
Learning Rate
प्रभाव
बहुत छोटा (η≪1)
Training धीमी होगी
बहुत बड़ा (η≫1)
Model सही direction में नहीं सीख पाएगा
संतुलित (η ठीक)
Loss धीरे-धीरे कम होगा और model सटीक होगा
🔹 8. Gradient Descent के प्रकार
प्रकार
विवरण
Batch Gradient Descent
सभी डेटा से gradient निकालता है – धीमा पर सटीक
Stochastic GD (SGD)
एक उदाहरण से gradient – तेज़ पर अशांत
Mini-batch GD
कुछ उदाहरणों से gradient – तेजी और स्थिरता का संतुलन
🔹 9. Optimization Techniques (GD का उन्नत रूप)
📌 1. SGD (Stochastic Gradient Descent)
हर सैंपल पर वेट अपडेट – noisy पर तेज़
📌 2. Momentum
Gradient की दिशा में “गति” जोड़ता है – तेज़ और smooth convergence
📌 3. RMSProp
हर वेट के लिए learning rate adapt करता है – बेहतर stability
📌 4. Adam (Most Popular)
Momentum + RMSProp का मेल – कम समय में बेहतर परिणाम
💻 आवश्यक कोड (PyTorch में Optimizer का प्रयोग)
import torch import torch.nn as nn import torch.optim as optim
model = nn.Linear(1, 1) # एक सिंपल मॉडल criterion = nn.MSELoss() # Loss function optimizer = optim.SGD(model.parameters(), lr=0.01) # Optimizer
# Forward + Backward + Optimize for epoch in range(10): inputs = torch.tensor([[1.0]]) targets = torch.tensor([[2.0]])
outputs = model(inputs) loss = criterion(outputs, targets)
Transfer Learning एक ऐसी Deep Learning तकनीक है जिसमें हम किसी पहले से trained मॉडल (जैसे GPT, BERT, ResNet, VGG आदि) को नए कार्य (task) के लिए उपयोग करते हैं।
✅ सरल भाषा में: “किसी चीज़ को पहले से सीखा हुआ दिमाग (model) लेकर, उसे नया काम सिखाना।”
🔧 उदाहरण:
मान लीजिए Google का मॉडल पहले से 10 लाख चित्रों पर train हो चुका है (जैसे ResNet)। अब आप उसे अपने 1000 इमेज वाले छोटे dataset पर उपयोग करना चाहते हैं। तो आप:
इस बड़े trained मॉडल को लेते हैं,
उसकी आखिरी कुछ layers हटाते हैं,
और अपनी पसंद के काम पर train करते हैं।
🛠️ 2. Fine-tuning क्या है?
Fine-tuning = Transfer Learning का अगला step
जब आप एक pretrained मॉडल को अपने विशेष टास्क (जैसे Cat/Dog classification, Hindi sentiment analysis) के लिए थोड़े बहुत बदलाव (modification) के साथ फिर से train करते हैं, तो इसे Fine-tuning कहते हैं।
⚙️ Process:
Pretrained model load करो (जैसे GPT, BERT, ResNet)
Top layers हटाओ या freeze करो
अपने नए dataset से output layers जोड़ो
केवल कुछ layers को train करो (low learning rate)
Model Fine-tune हो गया – अब यह नए कार्य में भी अच्छा करेगा
🤖 क्यों ज़रूरी है ये?
कारण
लाभ
कम डेटा
खुद से training करने की ज़रूरत नहीं
तेज़ training
मॉडल पहले से बहुत कुछ सीख चुका होता है
कम लागत
GPU समय और पैसे की बचत
बेहतर Accuracy
कम डेटा पर भी अच्छा प्रदर्शन
🌍 Real-world उदाहरण
मॉडल
Transfer Learning कार्य
BERT
Hindi Sentiment Analysis में उपयोग
ResNet
Medical X-Ray Images पर रोग पहचान
GPT
Legal Documents का सारांश बनाना
CLIP
Image+Text Matching in E-commerce
🎓 तुलना तालिका
बिंदु
Transfer Learning
Fine-tuning
क्या है?
Pretrained model reuse करना
Pretrained model को थोड़ा retrain करना
Data ज़रूरत
कम
थोड़ा और डेटा चाहिए
Training Time
तेज़
थोड़ा अधिक
Accuracy
अच्छी
और बेहतर (specific task पर)
🧠 एक उदाहरण (Human Analogy):
आप पहले से English बोलना जानते हैं (Pretrained), अब आपको IELTS exam की तैयारी करनी है (Fine-tuning)। आपका दिमाग transfer हुआ, अब उसे थोड़ा fine-tune किया गया।
✅ निष्कर्ष (Conclusion)
Transfer Learning = पुराने ज्ञान को नए काम में लगाना
Fine-tuning = उस पुराने ज्ञान को हल्का सा नया काम सिखाना
यह Deep Learning की दुनिया में Efficiency और Performance को बढ़ाने का सबसे लोकप्रिय तरीका बन चुका है।
(रेखीय बीजगणित की मूल बातें: मैट्रिक्स, वेक्टर और टेन्सर)
🔷 2.1 परिचय (Introduction)
Deep Learning मॉडल, विशेष रूप से Neural Networks, मुख्य रूप से संख्याओं (numbers) के साथ काम करते हैं। इन संख्याओं को संगठित और प्रोसेस करने के लिए हम Linear Algebra की तकनीकों का उपयोग करते हैं।
🧮 2.2 वेक्टर (Vectors)
➤ परिभाषा:
वेक्टर एक ऐसी सूची है जिसमें संख्याएँ एक विशेष क्रम में होती हैं। यह 1D array होता है।
उदाहरण:
✅ उपयोग:
Neural Network के inputs और weights को वेक्टर में संग्रहित किया जाता है।
वेक्टर dot product और angle measurement में प्रयोग होते हैं।
🛠️ वेक्टर ऑपरेशन:
क्रिया
उदाहरण
जोड़
[1,2]+[3,4]=[4,6]
स्केलर गुणा
3×[1,2]=[3,6]
डॉट प्रोडक्ट
[1,2]⋅[3,4]=1×3+2×4=11
🟦 2.3 मैट्रिक्स (Matrix)
➤ परिभाषा:
Matrix एक 2D array होता है जिसमें rows और columns होते हैं। यह वेक्टर का विस्तार है।
उदाहरण:
✅ उपयोग:
Neural Networks में inputs, weights, और activations को Matrix के रूप में रखा जाता है।
Matrix multiplication द्वारा layers के बीच data forward होता है।
🛠️ Matrix Operations:
क्रिया
विवरण
Transpose
पंक्ति को स्तंभ में बदलना
Multiplication
m×n×n×p = m×p
Identity Matrix
I, जहां A⋅I=A
Inverse (A⁻¹)
केवल कुछ matrices के लिए संभव
🧊 2.4 टेन्सर (Tensors)
➤ परिभाषा:
Tensors वेक्टर और मैट्रिक्स का सामान्यीकृत रूप है।
वेक्टर = 1D टेन्सर
मैट्रिक्स = 2D टेन्सर
3D+ arrays = Higher Order Tensors
उदाहरण:
import torch x = torch.rand(2, 3, 4) # 3D Tensor (2×3×4)
✅ उपयोग:
Deep Learning frameworks (जैसे PyTorch, TensorFlow) का मुख्य डेटा structure टेन्सर है।
Multidimensional डेटा को efficiently store और process करने के लिए।
🔄 2.5 Vector, Matrix, Tensor तुलना तालिका:
गुण
वेक्टर
मैट्रिक्स
टेन्सर
आयाम (Dimensions)
1D
2D
ND (3D, 4D…)
रूप
[x,y,z]
[[a,b],[c,d]]
[[[]]]
उपयोग
Input, Output
Layer Weights
Images, Sequences
🔧 2.6 Deep Learning में Linear Algebra का प्रयोग
क्षेत्र
Linear Algebra उपयोग
Input Data
Vectors / Tensors
Layer Weights
Matrix Multiplication
Feature Extraction
Dot Product
Backpropagation
Gradient Computation using Matrix derivatives
Images
Tensors of size (Channels × Height × Width)
🧠 उदाहरण:
PyTorch Code Example (Matrix multiplication):
import torch
A = torch.tensor([[1., 2.], [3., 4.]]) B = torch.tensor([[2., 0.], [1., 2.]]) result = torch.matmul(A, B)
print("Matrix A × B =\n", result)
Output:
Matrix A × B = tensor([[ 4., 4.], [10., 8.]])
📚 अभ्यास प्रश्न (Quiz)
❓Q1. वेक्टर और मैट्रिक्स में क्या अंतर है? ✅ वेक्टर 1D array है, जबकि मैट्रिक्स 2D array है।
❓Q2. Dot Product का उपयोग Neural Network में कहाँ होता है? ✅ Input और Weights के बीच के संबंध की गणना के लिए
❓Q3. टेन्सर क्या होता है? ✅ एक ND array जो वेक्टर और मैट्रिक्स दोनों को generalize करता है।
❓Q4. PyTorch या TensorFlow किस डेटा structure का उपयोग करते हैं? ✅ Tensor
✅ निष्कर्ष (Conclusion)
Linear Algebra Deep Learning की गणितीय रीढ़ है।
Vectors input/output को दर्शाते हैं
Matrices weights और connections को संभालते हैं
Tensors complex data (जैसे images, sequences) को efficiently represent करते हैं
इस अध्याय की समझ आगे के मॉडल्स, training और optimization को गहराई से समझने में मदद करेगी।