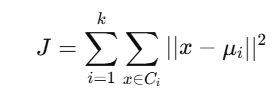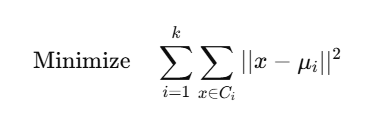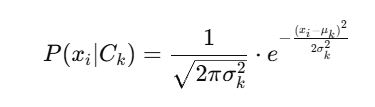Hierarchical Clustering एक ऐसा algorithm है जो डेटा को छोटे clusters से शुरू करके धीरे-धीरे उन्हें merge करता है, जिससे एक Tree-like Structure (Dendrogram) बनता है।यह Unsupervised Learning का एक और महत्वपूर्ण algorithm है जो clustering को सभी levels पर hierarchical रूप में करता है:
सोचिए:
पहले व्यक्ति को परिवारों में बांटा गया → फिर परिवार को समाजों में → फिर समाज को राज्यों में।
यही काम करता है Hierarchical Clustering।
🔶 Clustering Approaches:
| Method | Description |
|---|---|
| Agglomerative | Bottom-Up: हर point एक cluster से शुरू करता है → फिर merge होते हैं |
| Divisive | Top-Down: पूरा dataset एक cluster है → फिर split होते हैं |
👉 सबसे सामान्य तरीका: Agglomerative Clustering
🧠 Algorithm Steps (Agglomerative):
- हर data point को एक अलग cluster मानो
- Closest दो clusters को merge करो
- Distance matrix update करो
- Step 2 और 3 को तब तक दोहराओ जब तक एक ही cluster न बच जाए
🔍 Linkage Criteria (क्लस्टर्स के बीच दूरी कैसे मापें?)
| Linkage Type | Definition |
|---|---|
| Single | Closest points के बीच की दूरी |
| Complete | Farthest points के बीच की दूरी |
| Average | सभी pairwise distances का average |
| Ward | Variance को minimize करता है (default) |
📐 Distance Calculation:
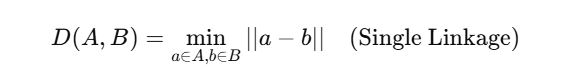
✅ Python Code (SciPy + Matplotlib):
import numpy as np
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage
# Sample Data
X = np.array([[1, 2],
[2, 3],
[5, 8],
[6, 9]])
# Step 1: Linkage matrix
Z = linkage(X, method='ward')
# Step 2: Dendrogram Plot
plt.figure(figsize=(8, 5))
dendrogram(Z, labels=["A", "B", "C", "D"])
plt.title("Hierarchical Clustering Dendrogram")
plt.xlabel("Data Points")
plt.ylabel("Distance")
plt.show()
🌲 Dendrogram क्या दर्शाता है?
Dendrogram एक tree diagram होता है जो दिखाता है कि कैसे data points और clusters आपस में जुड़े हुए हैं।
- Y-axis = merging distance
- Horizontal cuts = Desired number of clusters
✂️ अगर आप Y-axis पर एक horizontal लाइन खींचें → आपको अलग-अलग clusters मिलेंगे।
🔧 Clustering का निर्माण (sklearn):
from sklearn.cluster import AgglomerativeClustering
model = AgglomerativeClustering(n_clusters=2)
model.fit(X)
print("Cluster Labels:", model.labels_)
🔬 Use Cases:
| क्षेत्र | उदाहरण |
|---|---|
| Bioinformatics | Gene expression analysis |
| Marketing | Customer segmentation |
| Sociology | Social group formation |
| Document Analysis | Document/topic clustering |
⚖️ Pros & Cons:
✅ फायदे:
- कोई need नहीं है k (cluster count) को पहले से जानने की
- Dendrogram से cluster insights आसानी से मिलते हैं
- Complex shape वाले clusters को भी पकड़ सकता है
❌ नुकसान:
- बड़े datasets पर slow होता है
- Distance metrics और linkage method पर भारी निर्भरता
- Non-scalable for huge data
📊 Summary Table:
| Feature | Hierarchical Clustering |
|---|---|
| Input | Only Features (No Labels) |
| Output | Cluster assignments + Dendrogram |
| Method | Agglomerative / Divisive |
| Speed | Slow (high computational cost) |
| Visualization | Dendrogram |
📝 Practice Questions:
- Hierarchical Clustering कैसे कार्य करता है?
- Agglomerative vs Divisive clustering में क्या अंतर है?
- Linkage criteria में Ward method क्यों उपयोगी है?
- Dendrogram कैसे interpret किया जाता है?
- क्या Hierarchical Clustering large datasets के लिए उपयुक्त है?