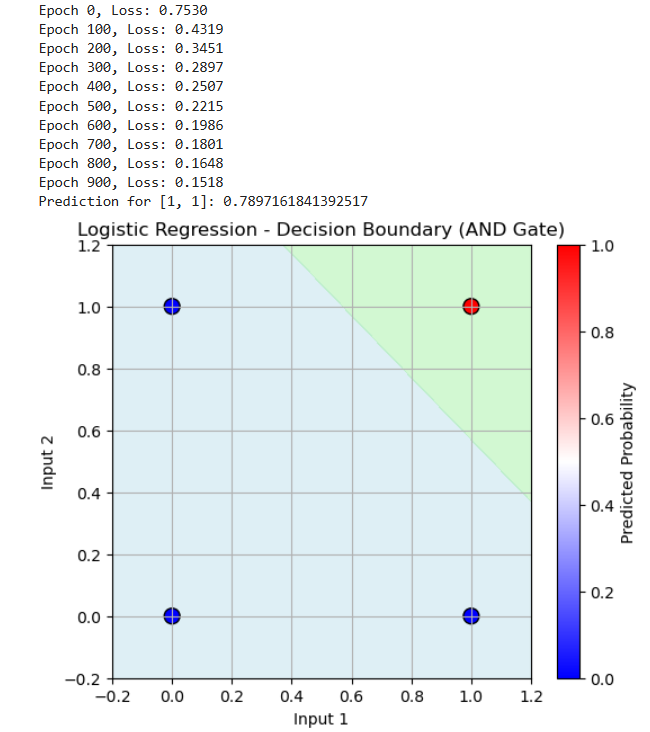
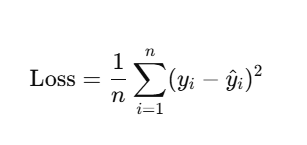🔷 परिचय:
Decision Trees और Random Forest Supervised Learning के दो बहुत लोकप्रिय और शक्तिशाली एल्गोरिद्म हैं।
ये विशेष रूप से तब उपयोगी होते हैं जब हमें explainable और interpretive मॉडल चाहिए होते हैं।
आप सोचिए एक इंसान कैसे फैसला करता है?
अगर “Age > 30” है → फिर “Income > ₹50k” → फिर निर्णय लें
ऐसा ही काम करता है Decision Tree.
🔶 1. Decision Tree (निर्णय वृक्ष)
📌 क्या है?
Decision Tree एक ट्री-आधारित मॉडल है जो डेटा को विभाजित (Split) करता है ताकि decision तक पहुँचा जा सके।
📊 उदाहरण:
आयु > 30?
/ \
हाँ नहीं
/ \
वेतन > 50k? No
/ \
हाँ नहीं
Yes No
✅ विशेषताएँ:
| विशेषता | विवरण |
|---|---|
| Model Type | Classification या Regression |
| Input Data | Structured tabular data |
| Output | Class label या Continuous value |
| Splitting Basis | Gini, Entropy, या MSE |
| Explainability | बहुत अच्छी |
🛠️ Decision Tree कैसे बनता है?
- Dataset के किसी feature पर split करो
- Split के बाद Impurity कम होनी चाहिए (Gini या Entropy)
- यही recursively करते हुए tree expand होता है
- Leaf nodes पर final class या value तय होती है
✅ स्किकिट-लर्न (Scikit-Learn) कोड:
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(criterion='gini') # या entropy
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
🔷 2. Random Forest (रैंडम फॉरेस्ट)
📌 क्या है?
Random Forest एक ensemble learning तकनीक है जो कई Decision Trees को मिलाकर एक मजबूत मॉडल बनाती है।
एक Decision Tree = एक डॉक्टर की राय
Random Forest = 100 डॉक्टरों की राय का औसत
अधिक Trees → बेहतर फैसला
✅ विशेषताएँ:
| विशेषता | विवरण |
|---|---|
| Algorithm Type | Bagging (Bootstrap Aggregation) |
| Model Strength | High Accuracy, Low Variance |
| Overfitting | कम होता है |
| Decision Method | Voting (Classification) / Averaging (Regression) |
🛠️ कैसे काम करता है?
- Dataset से random sampling के कई subsets बनते हैं
- हर subset पर एक अलग Decision Tree train होता है
- Prediction के समय: सभी trees की राय ली जाती है
- Final prediction: Majority Vote या Average
✅ स्किकिट-लर्न कोड:
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100, criterion='gini')
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
🔍 Decision Tree vs Random Forest
| विशेषता | Decision Tree | Random Forest |
|---|---|---|
| Accuracy | Medium | High |
| Overfitting Risk | High | Low |
| Explainability | High | Low |
| Speed | Fast | Slower (more trees) |
| Use Cases | Simple decision making | High performance tasks |
📊 Summary Table:
| Algorithm | Type | Strength | Common Use Cases |
|---|---|---|---|
| Decision Tree | Single Model | Easy to interpret | Credit scoring, Rules |
| Random Forest | Ensemble | Robust, less overfitting | Medical diagnosis, Finance |
📝 Practice Questions:
- Decision Tree किस principle पर काम करता है?
- Entropy और Gini Index में क्या अंतर है?
- Random Forest overfitting से कैसे बचाता है?
- Decision Tree explainable क्यों माना जाता है?
- एक real-life use case बताइए जहाँ Random Forest बेहतर है।