NLP की एक महत्वपूर्ण category — Sequence Models — की ओर बढ़ते हैं।
Text data inherently sequential होता है (हर word का order matter करता है), और इसी कारण हमें ऐसे models की ज़रूरत होती है जो sequence को याद रख सकें।
🔶 1. Sequence Data क्या होता है?
Text = शब्दों का क्रम (sequence of words):
जैसे: "मैं स्कूल जा रहा हूँ।"
यहाँ “जा रहा” और “जा रही” में फर्क होता है — क्रम मायने रखता है।
🧠 Sequence models का कार्य है – इस क्रम और संदर्भ को समझना।
🔁 2. Recurrent Neural Network (RNN)
📌 उद्देश्य:
- ऐसे model बनाना जो पिछले शब्दों का context याद रखकर अगला शब्द समझें या predict करें।
🔧 Working (Step-by-step):
हर समय step पर input आता है (word) और hidden state update होता है:
x₁ → x₂ → x₃ ...
↓ ↓ ↓
h₁ → h₂ → h₃ → Output

यह hidden state ht पिछली जानकारी को अगली word processing में उपयोग करता है।
⚠️ RNN की सीमाएं (Limitations)
| समस्या | विवरण |
|---|---|
| ❌ Vanishing Gradient | लंबे sentences में पिछले context की जानकारी खो जाती है |
| ❌ Fixed memory | पुराने शब्दों को ठीक से नहीं याद रख पाता |
| ❌ Slow training | Sequential nature के कारण parallelization कठिन |
🔄 3. LSTM (Long Short-Term Memory)
LSTM, RNN का एक बेहतर version है — जिसे इस समस्या को हल करने के लिए 1997 में Hochreiter & Schmidhuber ने प्रस्तावित किया।
📌 Core Idea:
LSTM में एक special memory cell होता है जो decide करता है कि कौन-सी जानकारी याद रखनी है, कौन-सी भूलनी है, और कौन-सी update करनी है।
🧠 Key Components of LSTM:
| Gate | Role |
|---|---|
| 🔒 Forget Gate | क्या भूलना है |
| 🔓 Input Gate | क्या जोड़ना है |
| 📤 Output Gate | अगले step में क्या भेजना है |
📊 LSTM Architecture (Flow)
Input xₜ → [Forget Gate, Input Gate, Output Gate] → Cell State → Output hₜ
LSTM sequence को ज़्यादा देर तक याद रखने में सक्षम होता है।
🔢 Equations (Simplified):
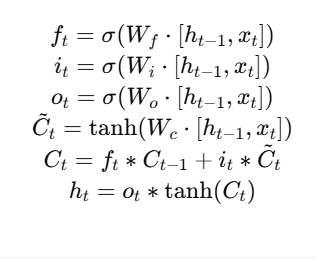
🧪 Practical Example:
📌 Use Case: Text Generation
- Input: “The sun”
- Output: “The sun is shining brightly today…”
LSTM last words को याद रखकर अगला word predict करता है।
🧰 Python Code Example (PyTorch)
import torch.nn as nn
class LSTMModel(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.lstm = nn.LSTM(embed_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, vocab_size)
def forward(self, x):
x = self.embedding(x)
out, _ = self.lstm(x)
out = self.fc(out)
return out
🤖 RNN vs LSTM Comparison
| Feature | RNN | LSTM |
|---|---|---|
| Memory | Short | Long |
| Gates | No | Yes (forget, input, output) |
| Vanishing Gradient | Common | Handled |
| Use Case | Simple patterns | Complex sequences |
📈 Applications of Sequence Models
| Task | Use |
|---|---|
| 🔤 Language Modeling | Next word prediction |
| ✍️ Text Generation | Poetry, story generation |
| 📧 Spam Detection | Sequential classification |
| 🎧 Speech Recognition | Audio-to-text |
| 🧠 Sentiment Analysis | Review understanding |
| 💬 Chatbots | Human-like conversation |
📝 Practice Questions:
- Sequence model की जरूरत NLP में क्यों पड़ती है?
- RNN का drawback क्या है?
- LSTM कैसे context याद रखता है?
- LSTM में तीन मुख्य gates कौन से हैं?
- एक छोटा सा PyTorch LSTM model का code लिखिए।
🧠 Summary Table
| Term | Meaning |
|---|---|
| RNN | Sequence modeling network |
| LSTM | Long-memory capable RNN |
| Gates | Decide memory control |
| Application | Text, audio, time-series |
| Limitation | RNN: short memory; LSTM: handles long-term context |