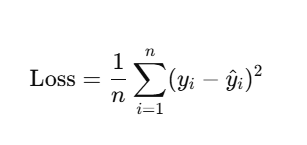🔷 परिचय:
Logistic Regression एक Supervised Learning Algorithm है जो Binary Classification समस्याओं के लिए उपयोग होता है।
यह Continuous Output (जैसे Linear Regression) नहीं देता, बल्कि Probability (0 से 1 के बीच) देता है।
उदाहरण:
ईमेल स्पैम है या नहीं? (Spam / Not Spam)
मरीज को बीमारी है या नहीं? (Yes / No)
🔶 क्यों Logistic?
Linear Regression में output कुछ भी हो सकता है: −∞ से +∞
लेकिन Classification में हमें output को Probability में बदलना होता है — इसलिए हम Sigmoid Function का उपयोग करते हैं।
🔢 फॉर्मूला:
🎯 Prediction Function:

🎯 Decision Rule:
- यदि y^0.5 → Class 1
- अन्यथा → Class 0
🔧 उपयोग के क्षेत्र:
| क्षेत्र | उपयोग |
|---|---|
| Email Filter | Spam vs Not Spam |
| हेल्थ | बीमारी है या नहीं |
| Finance | Loan Approve या Reject |
🔬 Logistic Regression in PyTorch
import torch
import torch.nn as nn
# Dummy data for AND logic gate
X = torch.tensor([[0.,0.],[0.,1.],[1.,0.],[1.,1.]], dtype=torch.float32)
y = torch.tensor([[0.],[0.],[0.],[1.]], dtype=torch.float32)
# Logistic Regression Model
class LogisticRegression(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(2, 1)
def forward(self, x):
return torch.sigmoid(self.linear(x))
model = LogisticRegression()
# Loss and Optimizer
criterion = nn.BCELoss() # Binary Cross Entropy Loss
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
# Training
for epoch in range(1000):
y_pred = model(X)
loss = criterion(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f"Epoch {epoch}, Loss: {loss.item():.4f}")
# Prediction
with torch.no_grad():
print("Prediction for [1, 1]:", model(torch.tensor([[1., 1.]])).item())
📊 Summary Table:
| Element | Description |
|---|---|
| Type | Classification |
| Input | Continuous (Features) |
| Output | Probability (0 to 1) |
| Activation | Sigmoid |
| Loss Function | Binary Cross Entropy (BCELoss) |
| PyTorch Layer | nn.Linear() + torch.sigmoid() |
Logistic Regression with Visualization (AND Gate)
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
# Dummy data (AND gate)
X = torch.tensor([[0.,0.],[0.,1.],[1.,0.],[1.,1.]], dtype=torch.float32)
y = torch.tensor([[0.],[0.],[0.],[1.]], dtype=torch.float32)
# Logistic Regression Model
class LogisticRegression(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(2, 1)
def forward(self, x):
return torch.sigmoid(self.linear(x))
model = LogisticRegression()
criterion = nn.BCELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
# Training
for epoch in range(1000):
y_pred = model(X)
loss = criterion(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f"Epoch {epoch}, Loss: {loss.item():.4f}")
# Prediction test
with torch.no_grad():
test_input = torch.tensor([[1., 1.]])
pred = model(test_input)
print("Prediction for [1, 1]:", pred.item())
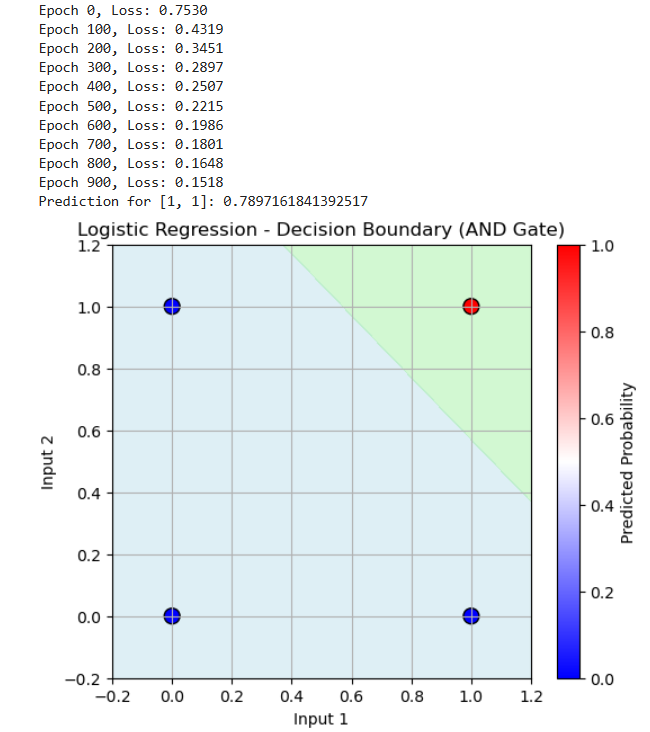
# ✅ Visualization Code Starts Here
# Convert to numpy for plotting
X_np = X.numpy()
y_np = y.numpy()
# Create a mesh grid
xx, yy = np.meshgrid(np.linspace(-0.2, 1.2, 100), np.linspace(-0.2, 1.2, 100))
grid = torch.tensor(np.c_[xx.ravel(), yy.ravel()], dtype=torch.float32)
with torch.no_grad():
probs = model(grid).reshape(xx.shape)
# Plot decision boundary
plt.figure(figsize=(6,5))
plt.contourf(xx, yy, probs, levels=[0, 0.5, 1], alpha=0.4, colors=['lightblue','lightgreen'])
plt.scatter(X_np[:,0], X_np[:,1], c=y_np[:,0], cmap='bwr', edgecolor='k', s=100)
plt.title("Logistic Regression - Decision Boundary (AND Gate)")
plt.xlabel("Input 1")
plt.ylabel("Input 2")
plt.colorbar(label='Predicted Probability')
plt.grid(True)
plt.show()
Output:
📝 Practice Questions:
- Logistic Regression को Classification के लिए क्यों उपयोग करते हैं?
- Sigmoid Function का role क्या होता है?
- Linear Regression और Logistic Regression में क्या मुख्य अंतर है?
- Binary Cross Entropy Loss क्या होता है?
- PyTorch में
model.parameters()का क्या उपयोग है?