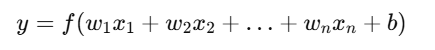(बैकप्रोपेगेशन और प्रशिक्षण प्रक्रिया)
🔷 1. Introduction (परिचय)
Backpropagation = “Backwards propagation of errors”
यह एक algorithm है जो Neural Network के weights को loss function के आधार पर update करता है।
🔁 2. Training का पूरा Flow
- Forward Pass:
Input → Hidden → Output
(Prediction generate होता है) - Loss Calculation:
Prediction और Ground Truth के बीच Loss मापा जाता है - Backward Pass (Backpropagation):
Loss का Gradient calculate होता है हर weight के लिए - Weight Update (Optimizer):
Gradient Descent द्वारा Weights को update किया जाता है - Repeat for Epochs:
जब तक model सटीक prediction न करने लगे
🔧 3. Backpropagation: कैसे काम करता है?
Backpropagation एक mathematical tool है जो Chain Rule of Calculus का उपयोग करता है:

जहाँ:
- L: Loss
- y: Prediction
- z: Neuron input
- w: Weight
🧠 Visual Diagram (Flowchart):
Input → Hidden → Output → Loss
↑
Backpropagate Gradient
↓
Update Weights (via Optimizer)
💻 PyTorch में Training Code (Simple)
import torch
import torch.nn as nn
import torch.optim as optim
# Simple Model
model = nn.Linear(1, 1)
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# Training Data
x = torch.tensor([[1.0], [2.0]])
y = torch.tensor([[2.0], [4.0]])
# Training Loop
for epoch in range(10):
outputs = model(x) # Forward
loss = criterion(outputs, y) # Compute Loss
optimizer.zero_grad() # Clear gradients
loss.backward() # Backpropagation
optimizer.step() # Update weights
print(f"Epoch {epoch+1}, Loss: {loss.item():.4f}")
🔍 Important Terms Recap
| Term | Explanation |
|---|---|
| Forward Pass | Prediction बनाना |
| Loss | गलती मापना |
| Backward Pass | Gradient निकालना |
| Optimizer | Weight update करना |
| Epoch | Dataset पर एक complete pass |
🎯 Learning Objectives Summary
- Backpropagation सीखने का आधार है
- यह Loss function के gradient के आधार पर weights को सुधारता है
- Optimizer gradient का उपयोग कर model को बेहतर बनाता है
- पूरा training loop PyTorch में automate होता है
📝 अभ्यास प्रश्न (Practice Questions)
- Backpropagation किस rule पर आधारित है?
- Forward Pass और Backward Pass में क्या अंतर है?
- Loss.backward() क्या करता है?
- Optimizer.zero_grad() क्यों ज़रूरी है?
- एक training loop के चार मुख्य steps क्या होते हैं?
Forward Pass and Loss Calculation
(फ़ॉरवर्ड पास और लॉस की गणना)
🔶 1. Forward Pass (इनपुट से आउपट तक की यात्रा)
Forward Pass वह चरण है जिसमें neural network किसी इनपुट को लेकर उसे विभिन्न layers के माध्यम से प्रवाहित करता है ताकि अंतिम output (prediction) उत्पन्न हो।
🔁 Step-by-Step Process:
- Input Vector (x) network में भेजा जाता है
- Each Layer:
- Performs a linear transformation

Applies an activation function

- Final output layer देता है prediction y^
🧠 Neural Network Flow:
scssCopyEditInput → Hidden Layer 1 → Hidden Layer 2 → ... → Output Layer → Prediction
- Linear + Activation sequence हर layer पर लागू होता है
- Output layer की activation function task पर निर्भर करती है (जैसे classification के लिए softmax या sigmoid)
📌 Forward Pass का उद्देश्य:
- Input features को progressively abstract करना
- Neural network के current weights से output generate करना
- इस output को असली label से compare कर पाने लायक बनाना
🔷 2. Loss Calculation (Prediction की ग़लती मापना)
Once prediction (y^) is ready, it is compared to the true label (y) using a Loss Function.
Loss function हमें बताता है prediction कितना सही या गलत है।
🔢 Common Loss Functions:

🔁 Loss Calculation का Flow:
- Prediction (y^) compute करो
- Ground truth label yसे compare करो
- Error calculate करो using loss function
- यही error backpropagation में propagate किया जाएगा
💻 PyTorch Example: Loss and Prediction
import torch
import torch.nn as nn
# Input and True label
x = torch.tensor([[1.0, 2.0]])
y_true = torch.tensor([[0.0]])
# Define simple model
model = nn.Sequential(
nn.Linear(2, 3),
nn.ReLU(),
nn.Linear(3, 1),
nn.Sigmoid()
)
# Loss function
criterion = nn.BCELoss()
# Forward Pass
y_pred = model(x)
# Loss Calculation
loss = criterion(y_pred, y_true)
print("Prediction:", y_pred.item())
print("Loss:", loss.item())
🔁 Complete Diagram Flow:
Input → Hidden → Output → Loss
↑
Backpropagate Gradient
↓
Update Weights (via Optimizer)
✅ यह दर्शाता है कि forward pass prediction करता है, और loss function उस prediction की गुणवत्ता को मापता है।
📌 Summary Table
| Step | Description |
|---|---|
| Forward Pass | Input को through layers भेजना |
| Output | Prediction generate करना |
| Loss Calculation | Prediction और label के बीच का अंतर मापना |
| Next Step | Loss को use करके gradient calculate करना |
🎯 Objectives Recap:
- Forward Pass transforms input → prediction
- Loss function tells how wrong the prediction is
- Loss is key for guiding weight updates
📝 Practice Questions:
- Forward Pass में कौन-कौन सी operations होती हैं?
- z=Wx+b का क्या अर्थ है?
- Binary Classification के लिए कौन-सा loss function उपयोग होता है?
- Loss function और optimizer में क्या अंतर है?
- PyTorch में loss calculate करने के लिए कौन-कौन सी steps होती हैं?