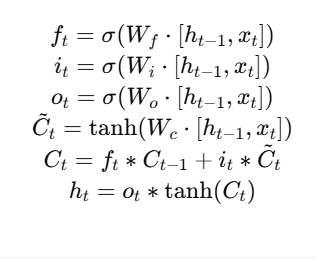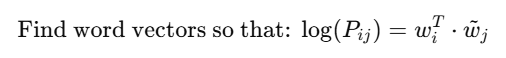अब हम NLP के सबसे क्रांतिकारी अविष्कारों की ओर बढ़ते हैं —
🚀 Transformers और BERT — जिन्होंने NLP की दुनिया को पूरी तरह बदल दिया है।
🔶 1. Transformers: Introduction
Transformer architecture 2017 में Google ने पेश किया, पेपर:
📄 “Attention is All You Need” — Vaswani et al.
इसने Recurrent Networks (RNN, LSTM) की dependency को हटा दिया और NLP को पूरी तरह से revolutionize कर दिया।
📐 Transformer की Key Idea: Self-Attention
हर word sentence के बाकी सभी words के context को साथ में समझता है, न कि केवल पिछले शब्दों को।
🔧 Architecture Overview
Transformer दो मुख्य हिस्सों में बंटा होता है:
[Encoder] →→→→→→→→→ [Decoder]
| Part | Role |
|---|---|
| Encoder | Input text को समझना (e.g., sentence meaning) |
| Decoder | Output generate करना (e.g., translation, caption) |
Note: BERT सिर्फ Encoder यूज़ करता है, GPT सिर्फ Decoder।
🔁 Self-Attention Mechanism
हर शब्द input में बाकी सभी शब्दों से relate करता है:
Sentence: "The cat sat on the mat"
"cat" → attends to "the", "sat", "mat" etc. via attention scores
🔢 Attention Equation:

जहाँ:
- Q: Query
- K: Key
- V: Value
- dk: Key vector dimension
⚙️ Transformer के Components:
| Component | Explanation |
|---|---|
| 🔹 Multi-Head Attention | Parallel attention layers for better learning |
| 🔹 Positional Encoding | Sequence order की जानकारी add करता है |
| 🔹 Feedforward Network | Linear + non-linear layers |
| 🔹 Layer Normalization | Stable training |
| 🔹 Residual Connections | Gradient flow बनाए रखता है |
🧠 2. BERT: Bidirectional Encoder Representations from Transformers
📄 “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” – Devlin et al., 2018
🎯 मुख्य उद्देश्य:
- Language Understanding — Chatbots, Q&A, classification
🔧 कैसे काम करता है?
- BERT केवल Transformer Encoder architecture पर आधारित है।
- यह दोनों तरफ के context को एक साथ पढ़ता है — इसलिए Bidirectional है।
📊 Pretraining Tasks:
- Masked Language Modeling (MLM)
- Sentence में कुछ शब्दों को mask किया जाता है, और model को predict करना होता है।
Input: "The [MASK] is shining" Output: "sun" - Next Sentence Prediction (NSP)
- दो sentences दिए जाते हैं — model को यह predict करना होता है कि दूसरा sentence पहले के बाद आता है या नहीं।
📦 Pretrained BERT Models:
| Variant | Description |
|---|---|
bert-base-uncased | Lowercase English, 12 layers |
bert-large-uncased | 24 layers, large model |
DistilBERT | Lightweight, faster |
Multilingual BERT | 100+ languages |
🔧 BERT Applications:
| Task | Example |
|---|---|
| ✅ Sentiment Analysis | “I love this product!” → Positive |
| 🧠 Question Answering | “Where is Taj Mahal?” → “Agra” |
| ✍️ Named Entity Recognition | “Barack Obama is from USA” → Person, Country |
| 💬 Chatbots | Intent understanding |
| 📃 Text Classification | News, spam, legal docs |
🧰 Example: HuggingFace Transformers
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertModel.from_pretrained("bert-base-uncased")
inputs = tokenizer("I love deep learning", return_tensors="pt")
outputs = model(**inputs)
🧠 Transformer vs BERT
| Aspect | Transformer | BERT |
|---|---|---|
| Type | General architecture | Pretrained NLP model |
| Structure | Encoder + Decoder | Only Encoder |
| Direction | Depends | Bidirectional |
| Application | Translation, captioning | Understanding, classification |
📈 Transformers & BERT Impact
| Area | Impact |
|---|---|
| 📚 Research | NLP को neural-level accuracy |
| 🗣️ Chatbots | Smarter conversations |
| 🧾 Legal/Medical | Automated document understanding |
| 🧠 AI Models | Foundation for GPT, T5, RoBERTa, etc. |
📝 Practice Questions:
- Transformer architecture में self-attention का क्या role है?
- BERT bidirectional क्यों है?
- Masked Language Modeling का मतलब क्या है?
- BERT किन NLP tasks के लिए use होता है?
- HuggingFace से BERT कैसे load करते हैं?
🧠 Summary Table
| Term | Description |
|---|---|
| Transformer | Sequence model using attention mechanism |
| BERT | Bidirectional encoder for NLP tasks |
| MLM | Mask words and predict |
| NSP | Predict sentence relationship |
| Applications | Q&A, classification, chatbot, NER |