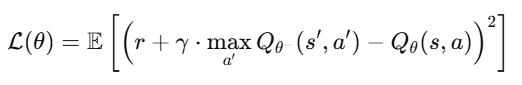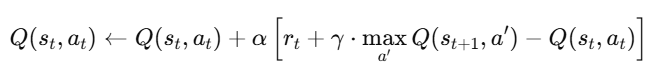आपने Reinforcement Learning की core technique Q-Learning को समझा — अब हम उसी का Deep Learning version सीखेंगे: 🧠 Deep Q-Network (DQN)
🔶 1. What is DQN?
Deep Q-Network (DQN) एक ऐसा algorithm है जो traditional Q-Learning को Deep Neural Network से combine करता है। जब state space बहुत बड़ा या continuous होता है (जैसे images, video frames), वहाँ Q-table बनाना possible नहीं होता — इसलिए हम use करते हैं Neural Network to approximate the Q-function: Q(s,a)≈Qθ(s,a)
🎯 “DQN maps states to Q-values using a deep neural network.”
📈 2. Why DQN?
Limitation of Q-Learning
DQN का समाधान
Large state-action space
Neural network approximation
Slow convergence
Experience replay
Instability in training
Target networks
🧠 3. Key Concepts in DQN
🔹 a) Q-Network
A deep neural network takes state as input
Outputs Q-values for each possible action
🔹 b) Experience Replay Buffer
Past experiences (s,a,r,s′) store किए जाते हैं
Random mini-batches से training होती है → reduces correlation
🔹 c) Target Network
Q-value targets एक fixed target network से लिए जाते हैं
Target network को हर कुछ steps पर update किया जाता है
इससे training stable होता है
🧪 4. DQN Architecture (High Level)
Input: State (e.g., image pixels) ↓ Convolutional Layers (if image input) ↓ Fully Connected Layers ↓ Output: Q-values for all possible actions
🔁 5. DQN Training Loop
Initialize Q-network (Q) and target network (Q_target) Initialize replay memory D
For each episode: Initialize state s For each step in episode: Choose action a using ε-greedy policy on Q(s) Execute action a → observe reward r and next state s' Store (s, a, r, s') in replay memory D
Sample random mini-batch from D: For each (s, a, r, s'): target = r + γ * max_a' Q_target(s', a') loss = (Q(s, a) - target)^2 Backpropagate and update Q
Every N steps: Q_target ← Q # update target network
अब हम Reinforcement Learning की सबसे प्रसिद्ध और foundational algorithm को समझेंगे — 🧠 Q-Learning
यह एक model-free reinforcement learning technique है, जिसे किसी भी environment में optimal decision-making के लिए use किया जाता है — बिना उसके अंदर के dynamics को जाने।
🔶 1. Q-Learning क्या है?
Q-Learning एक off-policy, model-free RL algorithm है जो agent को यह सीखने में मदद करता है कि किसी state में कौन-सा action लेने से long-term reward ज्यादा मिलेगा।
🎯 “Q-Learning finds the best action for each state — without needing to model the environment.”
📊 2. Key Idea: Learn Q-Value
📌 Q(s, a):
Q-value या Action-Value Function बताता है: “अगर agent state sss में है और action aaa लेता है, तो उसे future में कितना total reward मिल सकता है।”
Q(s,a)=Expected future reward
🧠 3. Bellman Equation for Q-Learning
Q-values को update करने के लिए हम use करते हैं Bellman update rule:
Symbol
Meaning
Q(s,a)
Q-value for state-action pair
α
Learning rate (0 to 1)
γ
Discount factor (importance of future reward)
rt
Immediate reward
maxa′Q(s′,a′)
Best future Q-value from next state
🔁 4. Q-Learning Algorithm Steps
Initialize Q(s, a) arbitrarily (e.g., all 0s) Repeat for each episode: Start at initial state s Repeat until terminal state: Choose action a using ε-greedy policy from Q(s, a) Take action a → observe reward r and next state s' Update Q(s, a) using Bellman equation Move to new state s ← s'
🔧 5. Example: Gridworld (Maze)
Imagine a 5×5 maze:
Agent starts at top-left
Goal is bottom-right
Agent learns which path gives maximum reward (shortest way)
अब हम Deep Learning की एक और शानदार शाखा की ओर बढ़ते हैं — 🎮 Reinforcement Learning (RL) जहाँ agent खुद से environment से सीखता है — trial and error के ज़रिए।
🔶 1. Reinforcement Learning क्या होता है?
Reinforcement Learning (RL) एक ऐसा learning paradigm है जिसमें एक agent environment में actions लेता है और rewards के आधार पर सीखता है कि कैसे बेहतर decision लिए जाएँ।
🎯 “RL is learning by interacting with the environment.”
🧠 Real-World Analogy:
Scenario
RL Mapping
बच्चा साइकिल चलाना सीखता है
Agent learns by falling & balancing
गेम खेलते समय स्कोर बढ़ाना
Agent earns reward by right actions
रेस्टोरेंट में नया खाना try करना
Exploration of unknown choices
🧩 2. Key Components of RL
Component
Description
🧠 Agent
जो decision लेता है (AI system)
🌍 Environment
जिसमें agent operate करता है
🎯 State (S)
वर्तमान स्थिति (e.g., board configuration)
🎮 Action (A)
जो कदम agent लेता है
💰 Reward (R)
Action के बदले मिलने वाली feedback
🔄 Policy (π)
Action लेने की strategy
🔮 Value Function (V)
किसी state की “future reward” expectation
🧮 Q-Value (Q)
Action के आधार पर reward की quality
🔁 3. RL का Interaction Cycle (Markov Decision Process – MDP)
अब हम समझते हैं GAN का Training Process, जो deep learning में सबसे रोचक और चुनौतीपूर्ण processes में से एक है। यह एक दो neural networks के बीच का “game” है — Generator vs Discriminator, जो एक-दूसरे को हराने की कोशिश करते हैं।
🔶 1. Overview: GAN कैसे Train होता है?
GAN दो parts से मिलकर बनता है:
Model
काम
🎨 Generator (G)
नकली data generate करता है
🕵️♂️ Discriminator (D)
Decide करता है कि data असली है या नकली
दोनों को बारी-बारी से train किया जाता है — Discriminator असली और नकली data में फर्क करना सीखता है, और Generator उसे बेवकूफ बनाने की कोशिश करता है।
🔁 2. Training Process Step-by-Step:
✅ Step 1: Real Data और Noise Prepare करें
एक mini-batch असली data x∼pdata से लें
Generator के लिए random noise vector z∼N(0,1) generate करें
✅ Step 2: Generator से Fake Data बनाएँ
Generator को noise vector zinput दें
वह fake sample generate करेगा: x^=G(z)
✅ Step 3: Discriminator को Train करें
उसे real data xxx और fake data x^ दोनों input दें
D को binary classification करना सिखाएँ:
D(x)→1
D(G(z))→0
Loss Function (Binary Cross-Entropy):
Discriminator के parameters को update करें
✅ Step 4: Generator को Train करें
अब Generator को better fake data generate करने के लिए update करें
उसके लिए Discriminator को fool करना लक्ष्य होता है:
Generator के parameters को update करें (Discriminator को freeze करके)
✅ Step 5: Repeat…
Step 1 से 4 को कई epochs तक repeat करें
धीरे-धीरे Generator realistic data generate करने लगेगा
और Discriminator उसे पहचानने में fail होने लगेगा (50% confidence)
🧠 PyTorch-Style Training Loop (Pseudo Code)
for epoch in range(num_epochs): for real_data in dataloader: