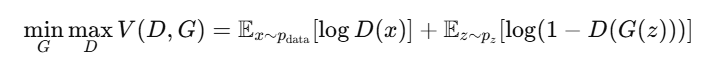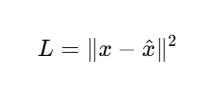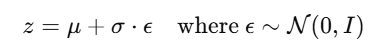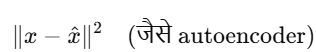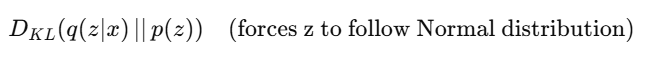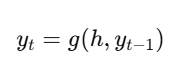अब हम GAN (Generative Adversarial Network) के दो सबसे महत्वपूर्ण components की तुलना करेंगे: 🎭 Generator vs Discriminator ये दोनों एक-दूसरे के विरोधी हैं, लेकिन साथ में मिलकर GAN को powerful बनाते हैं।
🔶 1. GAN का मूल विचार (Core Idea)
GAN architecture में दो models होते हैं:
Generator (G) — नकली data बनाता है
Discriminator (D) — बताता है कि data असली है या नकली
इन दोनों models का उद्देश्य होता है एक-दूसरे को beat करना। 👉 यही competition GAN को smart और creative बनाता है।
🧠 2. Role of Generator (G)
Feature
Description
🛠️ काम
Random noise से synthetic data generate करता है
🎯 Goal
इतना realistic data बनाना कि Discriminator उसे पहचान ना सके
🔄 Input
Random vector z∼N(0,1)
📤 Output
Fake image / data sample G(z)
🧠 सीखता है
कैसे असली data की नकल की जाए
“Generator एक कलाकार है — जो नकली चित्र बनाता है।”
🔧 Example:
z = torch.randn(64, 100) # Random noise fake_images = generator(z) # Generated samples
🧠 3. Role of Discriminator (D)
Feature
Description
🛠️ काम
Real और fake data में भेद करना
🎯 Goal
सही-सही पहचानना कि data असली है या नकली
🔄 Input
Data sample (real or fake)
📤 Output
Probability: Real (1) या Fake (0)
🧠 सीखता है
असली और नकली data के अंतर
“Discriminator एक जज है — जो असली और नकली पहचानता है।”
🔧 Example:
real_score = discriminator(real_images) # Output close to 1 fake_score = discriminator(fake_images) # Output close to 0
🔁 4. GAN Training Dynamics
चरण
विवरण
1️⃣ Generator एक नकली image बनाता है
Generator random noise vector z∼N(0,1)को लेकर fake image G(z) produce करता है।
2️⃣ Discriminator असली और नकली दोनों samples पर prediction करता है
Discriminator को एक batch असली data x और fake data G(z)का मिलता है, और वह predict करता है कि कौन सा sample असली है और कौन नकली।
3️⃣ Discriminator की loss को minimize किया जाता है
Discriminator को train किया जाता है ताकि वह असली samples को 1 और नकली samples को 0 classify कर सके (binary classification)।
4️⃣ अब Generator की बारी है — वो अपनी trick और smart बनाता है
Generator को train किया जाता है ताकि उसका fake output ऐसा हो कि Discriminator उसे “real” समझे। यानी वह Discriminator की prediction को गलत करने की कोशिश करता है।
5️⃣ यह process बार-बार दोहराई जाती है (adversarial loop)
इस adversarial game में दोनों models better होते जाते हैं। Generator बेहतर fake samples बनाता है, और Discriminator उन्हें पकड़ने में तेज़ होता है।
👉 इस loop से दोनों models बेहतर होते जाते हैं।
⚔️ 5. Comparison Table
Feature
Generator (G)
Discriminator (D)
उद्देश्य
नकली data बनाना
असली और नकली में अंतर करना
Input
Noise vector z
Data sample x
Output
Fake sample (image, text, etc.)
Probability (real or fake)
Target
Discriminator को धोखा देना
Generator को पकड़ना
Learns from
Discriminator के feedback से
Real vs fake examples से
Neural Net Type
Generator network (decoder जैसा)
Classifier network (binary)
📊 Visualization
Noise (z) ↓ [ Generator ] ↓ Fake Data ───► [ Discriminator ] ◄─── Real Data ↓ Predicts: Real or Fake?
📝 Practice Questions
Generator और Discriminator में क्या अंतर है?
Generator क्या generate करता है और किस input से?
Discriminator क्या predict करता है?
GAN training में दोनों networks एक-दूसरे से कैसे सीखते हैं?
अब हम deep learning की सबसे क्रांतिकारी और रचनात्मक तकनीक को समझने जा रहे हैं — 🎭 Generative Adversarial Networks (GANs)
यह deep learning का एक ऐसा क्षेत्र है जो machines को नई चीजें “create” करना सिखाता है — जैसे इंसानों की तरह तस्वीरें बनाना, आर्टिफिशियल आवाज़ें, नए फैशन डिज़ाइन, और यहां तक कि पूरी दुनिया की नक़ल करना।
🔶 1. What is a GAN?
GANs एक तरह का generative model है जो deep learning का उपयोग करके नई data instances generate करता है। GAN architecture में दो neural networks होते हैं जो एक-दूसरे के खिलाफ (adversarial) train होते हैं:
🎯 “एक network generate करता है, दूसरा उसे judge करता है।”
🔁 2. GAN Structure
Noise (z) ↓ [Generator Network] ↓ Fake Data (x̂) ↓ [Discriminator Network] ↑ ↓ Real Data (x) Real or Fake?
🔹 Generator (G):
Random noise से fake data generate करता है
इसका उद्देश्य है Discriminator को धोखा देना
🔹 Discriminator (D):
असली और नकली data के बीच अंतर करने की कोशिश करता है
इसका उद्देश्य है fake data को पकड़ना
🧠 3. Game Between Generator and Discriminator
Generator चाहता है कि Discriminator को धोखा दे
Discriminator चाहता है कि वो सही-सही असली और नकली data पहचान ले
You then train autoencoder with (noisy_img, original_img) pairs.
🧠 Use Cases:
Use
Description
🖼️ Image Denoising
Remove noise from pictures
📄 Document Cleanup
Clean scanned papers
📢 Audio Denoising
Remove background noise
🧠 Medical
Remove sensor noise in ECG, MRI, etc.
🔶 2. Application 2: Dimensionality Reduction
❓ What is it?
Autoencoder compresses high-dimensional data into a low-dimensional latent representation, similar to PCA (Principal Component Analysis) — but with non-linear capabilities.
🎯 “Autoencoder = Non-linear, trainable PCA”
📦 Example:
| Input | 784-dim vector (28×28 image) | Encoder | Reduces it to 2D or 3D latent code | Decoder | Reconstructs full image | Output | Use latent codes for clustering, visualization, etc.
🔧 PyTorch Sketch:
# Encoder output is just 2D self.encoder = nn.Sequential( nn.Linear(784, 128), nn.ReLU(), nn.Linear(128, 2) # 2D Latent Space )
🧠 Use Cases:
Use
Description
📊 Data Visualization
Compress to 2D for t-SNE / plots
🔍 Clustering
Group similar inputs (e.g., digits, faces)
⚡ Fast Inference
Work on lower-dimensional features
📈 Feature Extraction
Use compressed codes for ML models
🎮 Game AI
Compress game states
📝 Practice Questions:
Denoising Autoencoder क्या है और कैसे काम करता है?
Noise हटाने के लिए Autoencoder को कैसे train किया जाता है?
Dimensionality reduction में Autoencoder और PCA में क्या अंतर है?
Latent space का क्या role है?
Low-dimensional representation किन real-world problems में काम आता है?
अब हम Autoencoders की एक शक्तिशाली और probabilistic form को समझेंगे — 🔮 Variational Autoencoders (VAE) जो deep generative models की दुनिया में एक foundation की तरह माने जाते हैं।
🔶 1. What is a Variational Autoencoder?
VAE एक तरह का Autoencoder है, जो ना केवल input को compress करता है, बल्कि उसे एक probability distribution में encode करता है।
🎯 “VAE compress करता है input को एक distribution के रूप में, जिससे हम new data generate कर सकते हैं।”
🧠 2. Traditional Autoencoder vs VAE
Feature
Autoencoder
Variational Autoencoder
Output
Reconstruct input
Reconstruct + Sample new
Latent Vector
Fixed values
Probability distribution
Generation
No
Yes (Generative model)
Learning
Deterministic
Probabilistic
Regularization
None
KL Divergence
🔬 3. VAE Structure
Diagram:
Input x ↓ [Encoder Network] ↓ Latent Distribution (μ, σ) ↓ Sampling (z ~ N(μ, σ)) ↓ [Decoder Network] ↓ Reconstructed x̂
🧮 4. Latent Distribution
VAE encoder predicts:
Mean vector μ
Log-variance logσ2
From these, we sample latent variable
👉 इसे कहते हैं reparameterization trick ताकि gradient backpropagation संभव हो।
अब हम Deep Learning की सबसे शक्तिशाली और बहुप्रयुक्त संरचना को विस्तार से समझते हैं — 🔁 Encoder-Decoder Structure जिसका उपयोग NLP, Image Captioning, Machine Translation, Autoencoders आदि में बड़े पैमाने पर किया जाता है।
🔶 1. What is the Encoder-Decoder Architecture?
Encoder-Decoder एक ऐसा framework है जिसमें model दो मुख्य भागों में बँटा होता है:
Encoder: Input data को एक compact और meaningful representation (context vector या latent vector) में बदलता है।
Decoder: उसी compact representation से नया output sequence या data generate करता है।
🎯 “Encoder compress करता है, Decoder expand करता है।”
🧱 2. Structural Flow
Input Sequence / Data ↓ [Encoder] ↓ Latent Representation ↓ [Decoder] ↓ Output Sequence / Data
🔄 3. Encoder-Decoder is a General Pattern
Use Case
Input
Output
Encoder-Decoder
Translation
English sentence
French sentence
✅
Image Captioning
Image features
Text sentence
✅
Autoencoder
Image
Reconstructed image
✅
Chatbot
User query
Response
✅
Speech-to-text
Audio
Text
✅
🔧 4. Components of Encoder-Decoder
🔹 Encoder:
Sequence of layers (CNNs, RNNs, Transformers, etc.)
Learns to encode features from input
Outputs context/latent vector: h=f(x)
🔹 Decoder:
Takes the latent vector as input
Generates output step-by-step (esp. in sequence models)