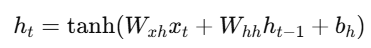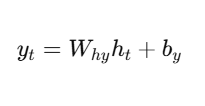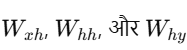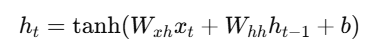(RNN में विलुप्त होता ग्रेडिएंट — कारण और समाधान)
अब हम RNN की सबसे बड़ी समस्या को समझेंगे —जिसके कारण deep RNNs को train करना कठिन हो जाता है:
🧨 Vanishing Gradient Problem
🔶 1. What is the Vanishing Gradient Problem?
जब neural network को train किया जाता है, तो हम backpropagation through time (BPTT) का उपयोग करते हैं ताकि हर time step पर gradient calculate किया जा सके।
लेकिन जैसे-जैसे sequence लंबा होता है और हम पीछे की ओर gradients propagate करते हैं —
gradient का मान बहुत छोटा (near zero) होता जाता है।
👉 इसे ही vanishing gradient कहते हैं।
🧮 2. Technical Explanation
RNN में hidden state update होता है:

⚠️ 3. Effects of Vanishing Gradient
| Effect | Description |
|---|---|
| No learning | पुराने inputs से कोई सीख नहीं होता |
| Short memory | RNN केवल recent inputs पर निर्भर करता है |
| Shallow reasoning | Long-term dependencies समझ नहीं पाता |
| Poor performance | Especially in long sequences (e.g. paragraph-level text) |
📉 4. Visualization
Imagine a gradient value like 0.8
→ Backprop through 50 steps:
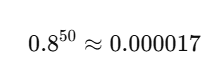
Gradient → 0 के बहुत करीब हो जाता है
→ Model पुराने शब्दों/steps को भूल जाता है।
🧪 5. Real-life Example
Suppose आपने ये वाक्य दिया:
“The movie was long, but in the end, it was incredibly good.”
Prediction चाहिए “good” शब्द के लिए।
Vanilla RNN में model शायद “long” या “but” को देख कर negative guess कर ले —
क्योंकि beginning में मौजूद words की जानकारी gradient vanish होने की वजह से खो जाती है।
🧯 6. How to Solve Vanishing Gradient?
| Solution | Description |
|---|---|
| ✅ LSTM (Long Short-Term Memory) | Introduces gates to control memory |
| ✅ GRU (Gated Recurrent Unit) | Simpler than LSTM, effective |
| 🔁 Gradient Clipping | Gradient को limit किया जाता है |
| ⏫ ReLU Activations | Vanishing कम होती है (compared to tanh) |
| 🧠 Better Initialization | Xavier/He initialization |
| 🧱 Skip Connections | जैसे ResNet में होता है |
🧠 7. Summary Table
| Feature | Normal RNN | LSTM/GRU |
|---|---|---|
| Memory | Short-term only | Long + short term |
| Gradient stability | Poor | Better |
| Sequence length handling | Weak | Strong |
| Complexity | Low | Medium to High |
🔧 PyTorch: Gradient Clipping Example
from torch.nn.utils import clip_grad_norm_
clip_grad_norm_(model.parameters(), max_norm=1.0)
📝 Practice Questions:
- Vanishing gradient क्या होता है?
- यह समस्या RNN में क्यों होती है?
- इसका क्या असर पड़ता है model की memory पर?
- इस समस्या को कैसे हल किया जा सकता है?
- LSTM और GRU इस समस्या से कैसे लड़ते हैं?
🎯 Summary
| Concept | Explanation |
|---|---|
| Vanishing Gradient | Gradient बहुत छोटा हो जाता है |
| Result | Model पुरानी जानकारी भूल जाता है |
| Main Cause | Long multiplication of small numbers |
| Solutions | LSTM, GRU, Clipping, ReLU |