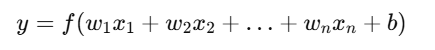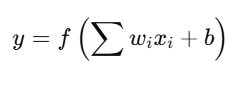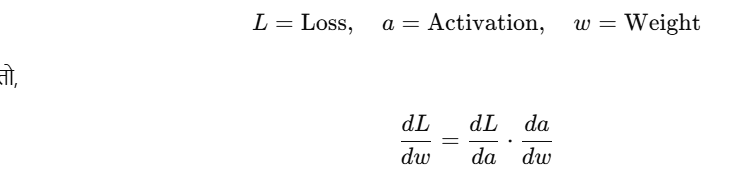(सक्रियण फलन: Sigmoid, Tanh, ReLU)
🔷 1. परिचय (Introduction)
Neural Network में Activation Function यह तय करता है कि कोई neuron “active” होगा या नहीं।
यह non-linearity लाता है, ताकि मॉडल complex patterns को सीख सके।
🔹 2. आवश्यकता क्यों? (Why Needed?)
बिना Activation Function के neural network एक simple linear model बन जाएगा।
📌 With Activation Function → Deep, non-linear models
📌 Without Activation → सिर्फ linear transformation
🔶 3. मुख्य Activation Functions
🔸 A. Sigmoid Function

📌 Output Range: (0, 1)
📌 उपयोग: Binary classification, Logistic regression
✅ लाभ:
- Probability की तरह आउटपुट देता है
- Smooth gradient
❌ कमी:
- Gradient vanishing problem
- Output range छोटा है
📈 ग्राफ: S-shaped (S-curve)

🔸 B. Tanh (Hyperbolic Tangent)

📌 Output Range: (-1, 1)
📌 उपयोग: जब input data zero-centered हो
✅ लाभ:
- Stronger gradients than sigmoid
- Centered at 0 → better learning
❌ कमी:
- Still suffers from vanishing gradient (large input पर gradient → 0)
📈 ग्राफ: S-shaped but centered at 0

🔸 C. ReLU (Rectified Linear Unit)

📌 Output Range: [0, ∞)
📌 उपयोग: Deep Networks में सबसे आम activation
✅ लाभ:
- Fast computation
- Sparse activation (only positive values pass)
- No vanishing gradient for positive inputs
❌ कमी:
- Dying ReLU Problem: negative input → always zero gradient
📈 ग्राफ: 0 for x < 0, linear for x > 0

🔁 तुलना तालिका (Comparison Table)
| Feature | Sigmoid | Tanh | ReLU |
|---|---|---|---|
| Output Range | (0, 1) | (-1, 1) | [0, ∞) |
| Non-linearity | ✅ | ✅ | ✅ |
| Vanishing Gradient | Yes | Yes | No (partial) |
| Speed | Slow | Slow | Fast |
| Usage | Binary outputs | Hidden layers (earlier) | Deep models (most common) |
💻 PyTorch Code: Activation Functions
import torch
import torch.nn.functional as F
x = torch.tensor([-2.0, 0.0, 2.0])
print("Sigmoid:", torch.sigmoid(x))
print("Tanh:", torch.tanh(x))
print("ReLU:", F.relu(x))
🎯 Learning Summary (सारांश)
- Sigmoid और Tanh smooth functions हैं लेकिन saturation (vanishing gradient) से ग्रस्त हो सकते हैं
- ReLU simple, fast, और deep networks में सबसे अधिक उपयोगी है
- Hidden layers में ReLU सबसे लोकप्रिय choice है
📝 अभ्यास प्रश्न (Practice Questions)
- Sigmoid और Tanh में क्या अंतर है?
- ReLU का गणितीय फॉर्मूला क्या है?
- Dying ReLU problem क्या है?
- यदि input -3 हो तो ReLU का output क्या होगा?
- नीचे दिए गए PyTorch कोड का आउटपुट बताइए:
x = torch.tensor([-1.0, 0.0, 1.0]) print(torch.tanh(x))