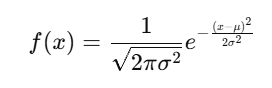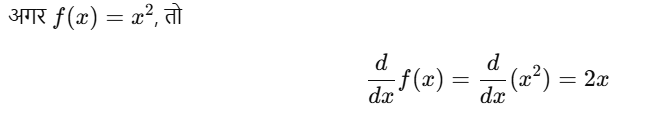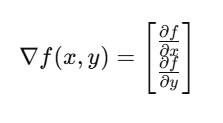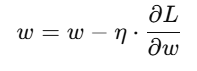(प्रायिकता और सांख्यिकी – Deep Learning की गणितीय नींव)
🔷 1. परिचय (Introduction)
Probability और Statistics, Deep Learning की अनिश्चितताओं से निपटने की क्षमता का आधार हैं। Neural Networks noisy data, uncertain predictions, और stochastic optimization पर आधारित होते हैं, इसलिए इन दोनों शाखाओं की समझ अत्यंत आवश्यक है।
🔢 2. Probability (प्रायिकता)
➤ परिभाषा:
Probability किसी घटना के घटने की संभावना को मापती है।
उदाहरण:
उदाहरण: सिक्का उछालने पर Head आने की प्रायिकता: P(Head)=1/2
📌 Deep Learning में उपयोग:
उपयोग क्षेत्र
भूमिका
Dropout
Randomly neurons को हटाना (probability आधारित)
Bayesian Neural Nets
Uncertainty modeling
Classification
Probabilities में output (Softmax)
Sampling
Random initialization, augmentation
📊 3. Statistics (सांख्यिकी)
➤ परिभाषा:
Statistics का कार्य है डेटा को संगठित करना, विश्लेषण करना और सारांश निकालना।
📌 मुख्य सांख्यिकीय माप:
माप
सूत्र/उदाहरण
Mean (औसत)
xˉ=1/n ∑xi
Median (मध्य)
मध्य मान (sorted list में बीच का मान)
Mode (मोड)
सबसे अधिक बार आने वाला मान
Variance (σ2)
1/ n ∑(xi−xˉ)2
Standard Deviation (σ)
sqrt Variance
📌 Deep Learning में Statistics के उपयोग:
क्षेत्र
उपयोग
Data Normalization
Mean & Std से scaling
BatchNorm Layers
Running Mean और Variance
Evaluation
Accuracy, Confusion Matrix
Loss Analysis
Distribution plotting (e.g., Histogram)
🧠 4. Random Variables & Distributions
➤ Random Variable:
ऐसा variable जो किसी प्रयोग के परिणाम पर निर्भर करता है।
➤ Common Distributions:
नाम
उपयोग
Bernoulli
Binary classification (0 या 1)
Binomial
Repeated binary trials
Normal (Gaussian)
Image, speech data – most natural data
Uniform
Random weight initialization
Poisson
Rare event modeling
📉 Normal Distribution Formula:
(Statistics & Probability in PyTorch)
import torch
# Random Normal Distribution Tensor data = torch.randn(1000)
Calculus, विशेष रूप से Differential Calculus, Deep Learning में उस प्रक्रिया को दर्शाता है जिससे हम यह समझते हैं कि एक फ़ंक्शन का आउटपुट, उसके इनपुट में हुए छोटे बदलाव से कैसे प्रभावित होता है।
Deep Learning में “Gradient Descent” और “Backpropagation” इन्हीं सिद्धांतों पर आधारित हैं।
🔹 2. Derivative क्या होता है?
➤ परिभाषा:
किसी फ़ंक्शन f(x) का Derivative यह बताता है कि x में एक छोटी-सी वृद्धि करने पर f(x) में कितना बदलाव आता है।
उदाहरण:
🔧 Deep Learning में उपयोग:
Derivative बताता है कि Loss Function कितनी तेज़ी से बदल रहा है।
इससे हम जान पाते हैं कि weights को बढ़ाना चाहिए या घटाना, ताकि Loss कम हो।
🔹 3. Chain Rule
जब एक फ़ंक्शन दूसरे फ़ंक्शन के अंदर छुपा हो (nested function), तब Derivative निकालने के लिए Chain Rule का उपयोग होता है।
उदाहरण:
🔁 Backpropagation इसी principle पर आधारित है – यह हर layer के output का derivative पिछले layers तक propagate करता है।
🔹 4. Gradient क्या है?
➤ परिभाषा:
Gradient, एक multi-variable function का vector derivative होता है। यह उस दिशा को दिखाता है जिसमें function सबसे तेजी से बढ़ता या घटता है।
➤ Deep Learning में Gradient का उपयोग:
Model के weights और biases को अपडेट करने के लिए
Gradient Descent के माध्यम से Loss को minimize करने के लिए
💻 आवश्यक कोड (PyTorch में Gradient निकालना)
import torch
# Variable with gradient tracking enabled x = torch.tensor(2.0, requires_grad=True)
Gradient Descent और Backpropagation में Calculus की भूमिका जानना
📝 अभ्यास प्रश्न (Practice Questions)
Derivative का Deep Learning में क्या कार्य है?
Chain Rule किसलिए उपयोग होता है?
Gradient क्या दर्शाता है और इसे क्यों निकाला जाता है?
यदि f(x)=x3 तो f′(x) क्या होगा?
नीचे दिए गए PyTorch कोड का आउटपुट बताइए:
6. नीचे दिए गए PyTorch कोड का आउटपुट बताइए:
x = torch.tensor(3.0, requires_grad=True) y = x**3 y.backward() print(x.grad)
🔹Deep Learning मॉडल का उद्देश्य होता है कि वह सही prediction करे। इसके लिए हमें Loss Function को न्यूनतम (minimize) करना होता है। यह कार्य Gradient Descent नाम की optimization तकनीक से होता है।
🔹 5. Gradient Descent क्या है?
➤ परिभाषा:
Gradient Descent एक iterative optimization algorithm है जिसका उपयोग Loss Function को कम करने के लिए किया जाता है। यह हमेसा gradient की उल्टी दिशा में चलता है – जहाँ loss कम होता है।
🔁 “उतरती पहाड़ी पर सही रास्ते से नीचे जाना।”
🔹 6. Gradient Descent का सूत्र
मान लीजिए हमारा वेट w है, और हमने उसका gradient निकाला है ∂L/∂w तो नया वेट होगा:
जहाँ:
η = Learning rate (0.001, 0.01 etc.)
∂L/∂w = Gradient of Loss function
🔹 7. Learning Rate का महत्व
Learning Rate
प्रभाव
बहुत छोटा (η≪1)
Training धीमी होगी
बहुत बड़ा (η≫1)
Model सही direction में नहीं सीख पाएगा
संतुलित (η ठीक)
Loss धीरे-धीरे कम होगा और model सटीक होगा
🔹 8. Gradient Descent के प्रकार
प्रकार
विवरण
Batch Gradient Descent
सभी डेटा से gradient निकालता है – धीमा पर सटीक
Stochastic GD (SGD)
एक उदाहरण से gradient – तेज़ पर अशांत
Mini-batch GD
कुछ उदाहरणों से gradient – तेजी और स्थिरता का संतुलन
🔹 9. Optimization Techniques (GD का उन्नत रूप)
📌 1. SGD (Stochastic Gradient Descent)
हर सैंपल पर वेट अपडेट – noisy पर तेज़
📌 2. Momentum
Gradient की दिशा में “गति” जोड़ता है – तेज़ और smooth convergence
📌 3. RMSProp
हर वेट के लिए learning rate adapt करता है – बेहतर stability
📌 4. Adam (Most Popular)
Momentum + RMSProp का मेल – कम समय में बेहतर परिणाम
💻 आवश्यक कोड (PyTorch में Optimizer का प्रयोग)
import torch import torch.nn as nn import torch.optim as optim
model = nn.Linear(1, 1) # एक सिंपल मॉडल criterion = nn.MSELoss() # Loss function optimizer = optim.SGD(model.parameters(), lr=0.01) # Optimizer
# Forward + Backward + Optimize for epoch in range(10): inputs = torch.tensor([[1.0]]) targets = torch.tensor([[2.0]])
outputs = model(inputs) loss = criterion(outputs, targets)
1943:McCulloch & Pitts ने पहला कृत्रिम न्यूरॉन मॉडल पेश किया। 👉 यह मॉडल Binary Input/Output पर आधारित था।
1958:Frank Rosenblatt ने Perceptron विकसित किया – पहला साधारण Neural Network। 👉 यह supervised learning में उपयोग हुआ।
🔹 1960s–1980s: रुचि में उतार-चढ़ाव
इस समय शोध जारी रहा लेकिन सीमित कंप्यूटिंग शक्ति और डाटा की कमी के कारण प्रगति धीमी रही।
1970s: Marvin Minsky ने Perceptron की सीमाओं को उजागर किया (XOR Problem) – इससे रुचि घट गई।
🔹 1986: Backpropagation क्रांति
Rumelhart, Hinton और Williams ने Backpropagation Algorithm को प्रस्तुत किया। 👉 इससे Multi-layer Neural Networks को training देना संभव हुआ।
🔹 1998: LeNet-5 और CNN का जन्म
Yann LeCun ने LeNet-5 CNN आर्किटेक्चर विकसित किया – इसे USPS डेटासेट पर हस्तलिखित अंकों की पहचान के लिए प्रयोग किया गया। 👉 यह पहला व्यावहारिक CNN मॉडल था।
🔹 2006: Deep Learning शब्द का आगमन
Geoffrey Hinton और साथियों ने Deep Belief Networks (DBNs) का प्रस्ताव रखा। 👉 यह unsupervised प्रीट्रेनिंग और deep structure learning की शुरुआत थी।
🔹 2012: AlexNet और ImageNet की जीत
Alex Krizhevsky, Ilya Sutskever और Geoffrey Hinton ने AlexNet नामक CNN बनाया।
इसने ImageNet प्रतियोगिता में पहला स्थान प्राप्त किया और Deep Learning को मुख्यधारा में ला दिया। ✅ Accuracy में भारी सुधार (Top-5 error rate: 26% → 15%)
🔹 2014: GANs और कल्पनाशील AI
Ian Goodfellow ने Generative Adversarial Networks (GANs) पेश किए। 👉 अब AI नया content बना सकता था – जैसे चित्र, चेहरा, संगीत।
🔹 2015–2018: Sequence Models और Attention
LSTM और GRU जैसे RNN आर्किटेक्चर लोकप्रिय हुए।
2017: Google ने Transformer पेपर प्रकाशित किया: “Attention is All You Need” 👉 NLP में क्रांति
🔹 2018–2020: BERT, GPT और Transfer Learning
BERT (Google) – Contextual understanding में सुधार
GPT (OpenAI) – Language generation में breakthrough
DALL·E, CLIP, Whisper – Vision + Text + Audio को जोड़ने वाले मॉडल
Diffusion Models – Stable Diffusion, Imagen द्वारा High-quality image generation
ChatGPT (GPT-3.5, GPT-4) – Large Language Models ने NLP, tutoring, content creation, आदि को बदल डाला
🔮 भविष्य की दिशा (Future Direction)
तकनीक
संभावित विकास
Self-supervised Learning
बिना लेबल के डेटा से सीखना
Explainable AI (XAI)
AI के निर्णयों को समझाना
Efficient AI
कम संसाधनों में बेहतर प्रदर्शन
Quantum + Deep Learning
भविष्य के हाइब्रिड मॉडल्स
🧾 सारांश तालिका (Timeline Summary)
वर्ष
मील का पत्थर (Milestone)
1943
पहला Artificial Neuron (McCulloch & Pitts)
1958
Perceptron (Rosenblatt)
1986
Backpropagation Algorithm
1998
LeNet-5 CNN
2006
Deep Belief Networks
2012
AlexNet – ImageNet जीत
2014
GANs – Content Generation
2017
Transformers – NLP में क्रांति
2020+
GPT, DALL·E, CLIP, Sora
🧠 अभ्यास प्रश्न (Practice Questions)
❓Q1. Perceptron किसने विकसित किया और कब? ✅ Frank Rosenblatt, 1958
❓Q2. Deep Learning शब्द को प्रचलित करने में किस मॉडल की भूमिका थी? ✅ Deep Belief Networks (2006)
❓Q3. AlexNet ने कौन सी प्रतियोगिता जीती और क्यों प्रसिद्ध हुआ? ✅ ImageNet 2012; CNN को प्रसिद्ध करने में भूमिका
❓Q4. Transformer मॉडल किस पेपर में पेश किया गया? ✅ “Attention is All You Need” (2017)
❓Q5. GANs का मुख्य योगदान क्या है? ✅ AI द्वारा नई सामग्री (जैसे चित्र) बनाना
✅ निष्कर्ष (Conclusion)
Deep Learning का विकास दशकों की मेहनत, अनुसंधान, और तकनीकी प्रगति का परिणाम है। 1943 में एक सरल न्यूरॉन से शुरू होकर आज यह तकनीक मानव जैसे सोचने, देखने, बोलने, और निर्णय लेने में सक्षम हो गई है।
Deep Learning आज लगभग हर प्रमुख क्षेत्र में उपयोग हो रहा है – स्वास्थ्य, शिक्षा, रक्षा, वित्त, ऑटोमोबाइल, मनोरंजन, भाषा, चित्र, आदि।
🖼️ 1. कंप्यूटर विज़न (Computer Vision)
उपयोग
विवरण
Face Recognition
मोबाइल फोन, CCTV में चेहरा पहचानना
Object Detection
वाहन, लोग, वस्तुएं पहचानना (जैसे YOLO, SSD मॉडल)
Medical Image Analysis
MRI, CT Scan, X-Ray से बीमारियाँ पहचानना
Self-Driving Cars
कैमरा से आने वाली छवियों को समझना और निर्णय लेना
Image Captioning
तस्वीरें देखकर उनके बारे में वाक्य बनाना
🗣️ 2. प्राकृतिक भाषा प्रसंस्करण (Natural Language Processing – NLP)
उपयोग
विवरण
Language Translation
Google Translate जैसी सेवाएं
Sentiment Analysis
ट्वीट या रिव्यू के भाव को समझना
Chatbots / Virtual Assistants
Alexa, Siri, Google Assistant
Question Answering
जैसे ChatGPT, BERT, GPT द्वारा जवाब देना
Text Summarization
लंबे लेखों का सारांश बनाना
🧠 3. हेल्थकेयर (Healthcare)
उपयोग
विवरण
Cancer Detection
Skin, breast, lung cancer को जल्दी पहचानना
Drug Discovery
नई दवाओं के प्रभाव की भविष्यवाणी करना
Medical Chatbots
रोगी से बात करके बीमारी का अनुमान लगाना
Genomics
DNA Sequencing और Genetic बीमारी की पहचान
🚗 4. ऑटोमोबाइल (Autonomous Vehicles)
उपयोग
विवरण
Self-driving Cars
Tesla, Waymo – सेंसर, कैमरा और DL आधारित नियंत्रण
Lane Detection
सड़क की रेखाओं की पहचान
Collision Prediction
टक्कर की संभावना का पूर्वानुमान
📈 5. वित्तीय क्षेत्र (Finance)
उपयोग
विवरण
Fraud Detection
बैंक ट्रांजैक्शन में धोखाधड़ी पकड़ना
Stock Market Prediction
शेयर की कीमतें अनुमानित करना
Credit Scoring
ऋण पात्रता का मूल्यांकन
🛰️ 6. डिफेंस और सुरक्षा (Defense & Security)
उपयोग
विवरण
Surveillance
वीडियो से संदिग्ध गतिविधियों की पहचान
Satellite Image Analysis
दुश्मन की गतिविधियों पर नजर
Target Detection
ड्रोन से लक्ष्य पहचानना
🎨 7. कला और रचनात्मकता (Art & Creativity)
उपयोग
विवरण
Image Generation
GANs द्वारा चित्र बनाना (जैसे DALL·E)
Music Composition
AI द्वारा नया संगीत बनाना
Style Transfer
एक चित्र की शैली को दूसरे में लगाना
📱 8. सोशल मीडिया और वेब एप्लीकेशन
उपयोग
विवरण
Recommendation Systems
Netflix, YouTube – आपके रुचि अनुसार सुझाव
Spam Detection
ईमेल में स्पैम की पहचान
Face Filters
Instagram/Snapchat – चेहरा पहचान कर फ़िल्टर लगाना
🧾 सारांश (Summary Table)
क्षेत्र
अनुप्रयोग उदाहरण
Vision
Face Detection, Object Classification
NLP
Chatbots, Machine Translation
Health
Cancer Diagnosis, Drug Prediction
Auto
Self-driving Cars, Lane Detection
Finance
Fraud Detection, Credit Scoring
Creativity
AI Art, Deepfake, GANs
📚 अभ्यास प्रश्न (Practice Questions)
❓Q1. Self-driving car में Deep Learning का कौन सा उपयोग होता है? ✅ सही उत्तर: कैमरा द्वारा वस्तु पहचानना और निर्णय लेना
❓Q2. ChatGPT किस प्रकार का Deep Learning आधारित अनुप्रयोग है? ✅ सही उत्तर: Natural Language Processing (NLP)
❓Q3. GANs का मुख्य उपयोग क्या है? ✅ सही उत्तर: नया कंटेंट (जैसे चित्र या वीडियो) बनाना
❓Q4. Recommendation System में Deep Learning का उदाहरण बताइए। ✅ सही उत्तर: YouTube या Netflix पर पसंद के अनुसार वीडियो सुझाना
✅ निष्कर्ष:
Deep Learning के अनुप्रयोगों की सीमा केवल कल्पना तक सीमित है। आज यह तकनीक मनुष्य के अनुभव को मशीनों में लाने का कार्य कर रही है — चाहे वह डॉक्टर हो, ड्राइवर, अनुवादक या चित्रकार।
(Difference between Machine Learning and Deep Learning)
🧠 1. परिभाषा पर आधारित अंतर
बिंदु
मशीन लर्निंग (Machine Learning)
डीप लर्निंग (Deep Learning)
परिभाषा
एक तकनीक जिसमें मॉडल इंसानों द्वारा बनाए गए फीचर्स से सीखता है
एक तकनीक जिसमें मॉडल खुद डेटा से फीचर्स सीखता है
निर्भरता
Manual feature extraction पर निर्भर
Automatic feature extraction
💾 2. डेटा आवश्यकता
बिंदु
मशीन लर्निंग
डीप लर्निंग
डेटा की मात्रा
कम डेटा पर भी ठीक काम करता है
अच्छे प्रदर्शन के लिए बहुत बड़ा डेटा चाहिए
⚙️ 3. एल्गोरिद्म और आर्किटेक्चर
बिंदु
मशीन लर्निंग
डीप लर्निंग
उदाहरण एल्गोरिद्म
Linear Regression, Decision Trees, SVM
CNN, RNN, Transformers
आर्किटेक्चर
सरल और व्याख्यात्मक
जटिल और गहराई में अनेक layers (deep)
🖥️ 4. हार्डवेयर और कंप्यूटिंग
बिंदु
मशीन लर्निंग
डीप लर्निंग
कंप्यूटेशन
CPU पर्याप्त होता है
GPU/TPU आवश्यक
Training Time
तेज़ (छोटे मॉडल)
धीमा (complex networks)
🧪 5. निष्पादन और प्रदर्शन
बिंदु
मशीन लर्निंग
डीप लर्निंग
Accuracy
सीमित, छोटे डेटा पर अच्छा
बड़े डेटा पर अत्यधिक सटीकता
Generalization
आसान
Overfitting की संभावना अधिक
🌍 6. अनुप्रयोग (Applications)
क्षेत्र
ML उदाहरण
DL उदाहरण
स्वास्थ्य
रोग की भविष्यवाणी (SVM)
कैंसर पहचान (CNN)
NLP
Spam Detection (Naive Bayes)
ChatGPT, BERT
विज़न
Simple Face Detection
Real-time Face Recognition
📌 सारांश तालिका
विशेषता
Machine Learning
Deep Learning
Feature Engineering
Manual
Automatic
डेटा आवश्यकता
कम
अधिक
Processing Power
Low
High
Interpretability
High
Low
Performance on Big Data
Limited
Excellent
Real-time Use
कभी-कभी
Yes (Voice Assistants, Autonomous Cars)
🎓 उदाहरण से समझें:
✅ Machine Learning: मान लीजिए आपको हाथ से लिखे हुए नंबर पहचानने हैं। आप manually कुछ features बनाएँगे: किनारों की गिनती, रेखाओं की दिशा आदि। फिर आप Decision Tree या SVM का प्रयोग करेंगे।
✅ Deep Learning: यह कार्य CNN खुद से सीख लेगा कि “0” और “8” में क्या फ़र्क है – बिना बताए कि किनारों या घुमाव को देखो।
📚 अभ्यास प्रश्न (Quiz)
❓Q1. Deep Learning में फीचर्स कैसे प्राप्त होते हैं? (A) Manual द्वारा (B) AutoML द्वारा (C) Model द्वारा स्वतः (D) डेटा साइंटिस्ट द्वारा ✅ सही उत्तर: (C)
❓Q2. किस तकनीक को बड़े डेटा पर बेहतर माना जाता है? (A) Machine Learning (B) Shallow Learning (C) Deep Learning (D) Linear Regression ✅ सही उत्तर: (C)
❓Q3. GPU किसमें आवश्यक होता है? (A) Traditional Algorithms (B) SVM (C) Deep Learning Neural Networks (D) HTML Rendering ✅ सही उत्तर: (C)