
Reinforcement Learning (RL) में एक एजेंट को एक वातावरण (Environment) में रखा जाता है।
वो किसी स्थिति (State) में होता है, वहाँ से एक Action लेता है, और बदले में उसे Reward मिलता है।
सोचिए एक रोबोट का, जो maze से बाहर निकलने की कोशिश कर रहा है — उसे सही रास्ता सीखने के लिए कई बार try करना होगा।
🔑 Key Concepts:
| Term | अर्थ (Meaning) |
|---|---|
| Agent | वह learner या decision-maker जो actions लेता है |
| Environment | बाहरी दुनिया जिससे agent interact करता है |
| State (S) | उस समय की स्थिति जहाँ agent है |
| Action (A) | agent द्वारा उठाया गया कदम या फैसला |
| Reward (R) | किसी action पर environment द्वारा दिया गया feedback |
| Policy (π) | Agent का strategy, जो बताती है किस state में कौनसा action लेना है |
| Value (V) | किसी स्थिति में मिलने वाले भविष्य के rewards का अनुमान |
| Episode | शुरू से लेकर एक goal तक का पूरा sequence |
🔄 Agent-Environment Loop:
यह एक continuous feedback loop होता है:
(State s_t) --[action a_t]--> (Environment) --[Reward r_t, next state s_{t+1}]--> (Agent)
Diagram:
+-----------+ action a_t +-------------+
| | -----------------------> | |
| AGENT | | ENVIRONMENT |
| | <----------------------- | |
+-----------+ r_t, s_{t+1} +-------------+
🧠 उद्देश्य:
Agent का लक्ष्य होता है:
Maximum cumulative reward (return) प्राप्त करना
Return:
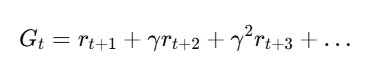
जहाँ
- γ: Discount Factor (0 < γ ≤ 1)
- Future rewards की importance को नियंत्रित करता है
🎮 उदाहरण:
| Problem | Agent | Environment | Reward |
|---|---|---|---|
| गेम खेलना (e.g. Chess) | Chess AI | Chess board | जीतने पर +1, हारने पर -1 |
| Self-driving car | Car controller | सड़क और ट्रैफिक | टकराने पर -ve, सही चलने पर +ve |
| Robo-navigation | Robot | Maze/Grid | Exit मिलने पर +10 |
🧮 Formal Definition (Markov Decision Process – MDP):
Reinforcement Learning को formal रूप में एक MDP से दर्शाया जा सकता है: MDP=(S,A,P,R,γ)
जहाँ:
- S: States का सेट
- A: Actions का सेट
- P: Transition probabilities
- R: Reward function
- γ: Discount factor
✅ Python Code Example (Gym Environment):
import gym
# Environment
env = gym.make("CartPole-v1")
state = env.reset()
for _ in range(10):
env.render()
action = env.action_space.sample() # Random action
next_state, reward, done, info = env.step(action)
print("Reward:", reward)
if done:
break
env.close()
🎯 Summary Table:
| Term | Description |
|---|---|
| Agent | Decision-maker (e.g., robot, AI model) |
| Environment | External system (e.g., game, world) |
| State | Current situation or context |
| Action | Agent का निर्णय या प्रयास |
| Reward | पर्यावरण का response, जो सीखने में मदद करता |
| Policy | नियम जो बताता है क्या करना है |
| Goal | Total reward को maximize करना |
📝 Practice Questions:
- Reinforcement Learning में Agent और Environment क्या भूमिका निभाते हैं?
- Reward और Return में क्या अंतर है?
- Discount factor (γ\gammaγ) क्या है और इसका महत्व क्या है?
- RL में Policy और Value function का क्या कार्य होता है?
- कोई real-life उदाहरण दीजिए जहाँ RL model प्रयोग हो सकता है।