
🔹 1. परिचय (Introduction)
Calculus, विशेष रूप से Differential Calculus, Deep Learning में उस प्रक्रिया को दर्शाता है जिससे हम यह समझते हैं कि एक फ़ंक्शन का आउटपुट, उसके इनपुट में हुए छोटे बदलाव से कैसे प्रभावित होता है।
Deep Learning में “Gradient Descent” और “Backpropagation” इन्हीं सिद्धांतों पर आधारित हैं।
🔹 2. Derivative क्या होता है?
➤ परिभाषा:
किसी फ़ंक्शन f(x) का Derivative यह बताता है कि x में एक छोटी-सी वृद्धि करने पर f(x) में कितना बदलाव आता है।
उदाहरण:
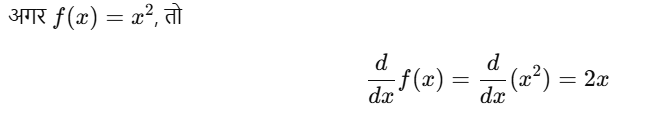
🔧 Deep Learning में उपयोग:
- Derivative बताता है कि Loss Function कितनी तेज़ी से बदल रहा है।
- इससे हम जान पाते हैं कि weights को बढ़ाना चाहिए या घटाना, ताकि Loss कम हो।
🔹 3. Chain Rule
जब एक फ़ंक्शन दूसरे फ़ंक्शन के अंदर छुपा हो (nested function), तब Derivative निकालने के लिए Chain Rule का उपयोग होता है।
उदाहरण:

🔁 Backpropagation इसी principle पर आधारित है – यह हर layer के output का derivative पिछले layers तक propagate करता है।
🔹 4. Gradient क्या है?
➤ परिभाषा:
Gradient, एक multi-variable function का vector derivative होता है। यह उस दिशा को दिखाता है जिसमें function सबसे तेजी से बढ़ता या घटता है।
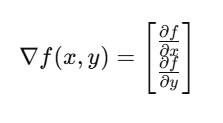
➤ Deep Learning में Gradient का उपयोग:
- Model के weights और biases को अपडेट करने के लिए
- Gradient Descent के माध्यम से Loss को minimize करने के लिए
💻 आवश्यक कोड (PyTorch में Gradient निकालना)
import torch
# Variable with gradient tracking enabled
x = torch.tensor(2.0, requires_grad=True)
# Function: f(x) = x^2
y = x**2
# Compute gradient
y.backward()
print("dy/dx at x=2:", x.grad) # Output: 4.0 (because dy/dx = 2x)
📌 वास्तविक उपयोग (Real Use in Deep Learning)
| Concept | Calculus उपयोग |
|---|---|
| Loss Function | Derivative से gradient निकालना |
| Optimizers | Gradient Descent step में |
| Backpropagation | Chain Rule से gradient को पीछे propagate करना |
| Regularization | Cost Function में derivative से नियंत्रण |
🎯 Chapter Objectives (लक्ष्य)
- Derivatives की बुनियादी समझ प्राप्त करना
- Chain Rule की अवधारणा को जानना
- Gradient के महत्व को समझना
- Gradient Descent और Backpropagation में Calculus की भूमिका जानना
📝 अभ्यास प्रश्न (Practice Questions)
- Derivative का Deep Learning में क्या कार्य है?
- Chain Rule किसलिए उपयोग होता है?
- Gradient क्या दर्शाता है और इसे क्यों निकाला जाता है?
- यदि f(x)=x3 तो f′(x) क्या होगा?
- नीचे दिए गए PyTorch कोड का आउटपुट बताइए:
6. नीचे दिए गए PyTorch कोड का आउटपुट बताइए:
x = torch.tensor(3.0, requires_grad=True)
y = x**3
y.backward()
print(x.grad)🔹Deep Learning मॉडल का उद्देश्य होता है कि वह सही prediction करे। इसके लिए हमें Loss Function को न्यूनतम (minimize) करना होता है।
यह कार्य Gradient Descent नाम की optimization तकनीक से होता है।
🔹 5. Gradient Descent क्या है?
➤ परिभाषा:
Gradient Descent एक iterative optimization algorithm है जिसका उपयोग Loss Function को कम करने के लिए किया जाता है।
यह हमेसा gradient की उल्टी दिशा में चलता है – जहाँ loss कम होता है।
🔁 “उतरती पहाड़ी पर सही रास्ते से नीचे जाना।”
🔹 6. Gradient Descent का सूत्र
मान लीजिए हमारा वेट w है, और हमने उसका gradient निकाला है ∂L/∂w तो नया वेट होगा:
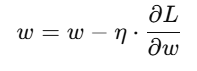
जहाँ:
- η = Learning rate (0.001, 0.01 etc.)
- ∂L/∂w = Gradient of Loss function
🔹 7. Learning Rate का महत्व
| Learning Rate | प्रभाव |
|---|---|
| बहुत छोटा (η≪1) | Training धीमी होगी |
| बहुत बड़ा (η≫1) | Model सही direction में नहीं सीख पाएगा |
| संतुलित (η ठीक) | Loss धीरे-धीरे कम होगा और model सटीक होगा |
🔹 8. Gradient Descent के प्रकार
| प्रकार | विवरण |
|---|---|
| Batch Gradient Descent | सभी डेटा से gradient निकालता है – धीमा पर सटीक |
| Stochastic GD (SGD) | एक उदाहरण से gradient – तेज़ पर अशांत |
| Mini-batch GD | कुछ उदाहरणों से gradient – तेजी और स्थिरता का संतुलन |
🔹 9. Optimization Techniques (GD का उन्नत रूप)
📌 1. SGD (Stochastic Gradient Descent)
हर सैंपल पर वेट अपडेट – noisy पर तेज़
📌 2. Momentum
Gradient की दिशा में “गति” जोड़ता है – तेज़ और smooth convergence
📌 3. RMSProp
हर वेट के लिए learning rate adapt करता है – बेहतर stability
📌 4. Adam (Most Popular)
Momentum + RMSProp का मेल – कम समय में बेहतर परिणाम
💻 आवश्यक कोड (PyTorch में Optimizer का प्रयोग)
import torch
import torch.nn as nn
import torch.optim as optim
model = nn.Linear(1, 1) # एक सिंपल मॉडल
criterion = nn.MSELoss() # Loss function
optimizer = optim.SGD(model.parameters(), lr=0.01) # Optimizer
# Forward + Backward + Optimize
for epoch in range(10):
inputs = torch.tensor([[1.0]])
targets = torch.tensor([[2.0]])
outputs = model(inputs)
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item():.4f}")
📌 Optimization Diagram (सैद्धांतिक)
Loss
│
│ ● ← Loss अधिक है
│ /
│ ●
│ /
│ ● ← Gradient Descent Steps
│/
●──────────── Weights
🎯 Chapter Objectives (लक्ष्य)
- Gradient Descent का मूल सिद्धांत समझना
- Loss को कम करने की प्रक्रिया जानना
- विभिन्न Optimization Techniques को पहचानना
- Learning Rate के प्रभाव को समझना
📝 अभ्यास प्रश्न (Practice Questions)
- Gradient Descent क्या है और Deep Learning में क्यों आवश्यक है?
- Learning Rate बहुत अधिक हो तो क्या दिक्कत हो सकती है?
- Momentum Optimizer किस concept पर आधारित है?
- Mini-batch Gradient Descent के क्या लाभ हैं?
- नीचे दिए गए कोड का उद्देश्य बताइए:
optimizer.zero_grad() loss.backward() optimizer.step()