
अब हम Reinforcement Learning की सबसे प्रसिद्ध और foundational algorithm को समझेंगे —
🧠 Q-Learning
यह एक model-free reinforcement learning technique है, जिसे किसी भी environment में optimal decision-making के लिए use किया जाता है — बिना उसके अंदर के dynamics को जाने।
🔶 1. Q-Learning क्या है?
Q-Learning एक off-policy, model-free RL algorithm है जो agent को यह सीखने में मदद करता है कि किसी state में कौन-सा action लेने से long-term reward ज्यादा मिलेगा।
🎯 “Q-Learning finds the best action for each state — without needing to model the environment.”
📊 2. Key Idea: Learn Q-Value
📌 Q(s, a):
- Q-value या Action-Value Function बताता है: “अगर agent state sss में है और action aaa लेता है, तो उसे future में कितना total reward मिल सकता है।”
Q(s,a)=Expected future reward
🧠 3. Bellman Equation for Q-Learning
Q-values को update करने के लिए हम use करते हैं Bellman update rule:
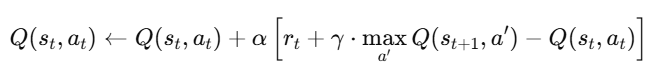
| Symbol | Meaning |
|---|---|
| Q(s,a) | Q-value for state-action pair |
| α | Learning rate (0 to 1) |
| γ | Discount factor (importance of future reward) |
| rt | Immediate reward |
| maxa′Q(s′,a′) | Best future Q-value from next state |
🔁 4. Q-Learning Algorithm Steps
Initialize Q(s, a) arbitrarily (e.g., all 0s)
Repeat for each episode:
Start at initial state s
Repeat until terminal state:
Choose action a using ε-greedy policy from Q(s, a)
Take action a → observe reward r and next state s'
Update Q(s, a) using Bellman equation
Move to new state s ← s'
🔧 5. Example: Gridworld (Maze)
Imagine a 5×5 maze:
- Agent starts at top-left
- Goal is bottom-right
- Agent learns which path gives maximum reward (shortest way)
Q[state][action] += alpha * (reward + gamma * max(Q[next_state]) - Q[state][action])
📈 6. Exploration vs Exploitation
- Exploration: Try new actions to discover better rewards
- Exploitation: Use known actions with best Q-values
👉 Use ε-greedy strategy:
- With probability ε → random action
- With probability (1–ε) → best action
📦 7. Summary Table
| Term | Description |
|---|---|
| Q(s, a) | Expected total reward for action aaa in state sss |
| α | Learning rate – कितनी तेज़ी से सीखना है |
| γ | Future rewards की importance |
| ε | Randomness (exploration) |
| Bellman Update | Q-values को improve करने का तरीका |
📝 Practice Questions:
- Q-learning को model-free क्यों कहा जाता है?
- Q-value क्या होता है?
- Bellman equation का role क्या है?
- ε-greedy strategy क्यों उपयोग होती है?
- Q-Learning और SARSA में क्या फर्क है?